11.4. Weitere Tipps und Tricks#
11.4.1. User Agent im HTTP-Header setzen#
In manchen Fällen kann es notwendig sein, den Header der HTTP-Anfrage zu bearbeiten. Standardmäßig wird in einer HTTP-Anfrage über das requests-Paket als User Agent das requests-Paket angegeben:
# Default-Header der HTTP-Anfrage
import requests
url = "https://chroniclingamerica.loc.gov/search/pages/results/?andtext=&phrasetext=book+review&format=json"
response = requests.get(url)
print(response.request.headers)
{'User-Agent': 'python-requests/2.32.3', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive'}
Macht es einen Unterschied, ob im Header als User Agent python-requests/2.29.0 oder Mozilla/5.0 (bzw. ein anderer Browser) steht? Ja, denn mit dem Default-Header erkennt der Server, dass die Anfrage von einer Webscraping Bibliothek ausgeht. Manche Websitebetreiber:innen behandeln solche Anfragen anders und schränken den Zugriff für solche Anfragen ein. Allerdings darf der User Agent nicht immer geändert werden, denn manche Nutzungsbedingungen schließen so eine Art der “Vortäuschung” explizit aus.
# User Agent im Request-Header ersetzen
headers = {'User-Agent': 'Mozilla/5.0'}
response = requests.get(url, headers=headers)
Wenn eine requests Session verwendet wird, muss der Header sogar nicht im Gesamten ersetzt werden, sondern es können einzelne Werte ganz einfach ausgetauscht werden. Laut requests-Dokumentationsseiten geht das wie folgt:
# s = requests.Session()
# s.headers.update({'User-Agent': 'Mozilla/5.0'})
Wenn ihr Schnittstellen öffentlicher Institutionen nutzt, ist es oft empfehlenswert, als User Agent den Namen des Forschungsprojekts anzugeben. Manche Websitebetreiber:innen bitten sogar explizit darum, wie beispielsweise die Betreiber:innen der API der Gemeinsamen Normdatei (lobid-gnd):
Wir bitten darum, bei der Nutzung von lobid eine aussagekräftige, wiederkehrende Zeichenkette als User Agent mitzusenden, damit wir bei der statistischen Auswertung unserer Infrastruktur Nutzungsweisen der API erkennen und unsere Dienstleistungen aus den gewonnenen Erkenntnissen verbessern können. Die statistische Erfassung der Nutzung dient außerdem der Begründung der Relevanz unserer Daten und Dienste gegenüber Geldgeber:innen und Entscheider:innen. In der Zeichenkette des User Agent kann sich die zugreifende Person, Institution oder ein Projekt zu erkennen geben, gegebenenfalls auch eine Kontaktmöglichkeit (E-Mail-Adresse) hinzufügen, eine anonyme beziehungsweise pseudonyme Kennung ist jedoch ebenso möglich. Eine solche Agent-Kennung sollte über die Dauer eines Projektes möglichst unverändert bleiben. (Quelle: lobid-gnd)
Der Name des Forschungsprojekts kann einfach als String anstelle von “Mozilla/5.0” angegeben werden; dabei könnt ihr z.B. auch einen Link zu einem GitHub-Repository angeben, in dem sich der Code des Web Scrapers befindet, oder eine E-Mail-Adresse, unter der ihr kontaktiert werden wollt.
11.4.2. Selenium im Headless Mode#
Bisher haben wir Selenium immer so verwendet, dass sich beim Aufruf einer Seite der automatisierte Chrome Browser geöffnet hat. Wenn ihr gerade dabei seid, den Code zu schreiben, die Web Scraping-Strategie zu planen und die extrahierten Daten zu überprüfen, dann empfiehlt es sich, den Browser in diesem “sichtbaren” Modus zu automatisieren. Aber wenn das Skript dann fertig ist und ihr nicht mehr im Browserfenster nachverfolgen müsst, ob alle Aktionen so ausgeführt werden wie gewünscht, könnt ihr den Browser auch im sogenannten “headless mode” automatisieren, bei dem sich das Browserfenster nicht öffnet:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
options = Options()
options.add_argument("--headless")
driver = webdriver.Chrome(options=options)
Der Webdriver kann mit weiteren Optionen konfiguriert werden. Eine Übersicht über alle Optionen findet ihr in den Selenium-Dokumentationsseiten.
11.4.3. HTTP Content Negotiation und Linked Data#
Im Zusammenhang mit REST APIs haben wir gesehen, dass verschiedene Dateiformate meist durch Angabe eines Parameters (z.B.: api/items/3492?format=json) oder durch Angabe der Dateiendung (z.B. api/items/3492.json) angefragt werden können. Allerdings sieht die HTTP Spezifikation, also die Sammlung von Dokumenten, in denen das HTTP-Protokoll beschrieben wird, einen eigenen Mechanismus für die Auswahl verschiedener Dateiformate vor, der sich “Content Negotiation” nennt. Dabei wird das Format einer Ressource direkt über den Accept-Parameter im HTTP-Header “ausgewählt”, oder, etwas genauer ausgedrückt, zwischen Client und Server “ausgehandelt” (engl. “negotiation”). Dieser Mechanismus wird insbesondere im Zusammenhang mit sogenannten Linked Data Datensätzen verwendet. Linked Data ist grob gesagt ein Ansatz, strukturierte Daten im Web bereitzustellen. Solche Daten sind meist nach einer ganz bestimmten Syntax und Logik strukturiert, die wir im Rahmen dieses Seminars nicht vertiefen können, und sie werden als Turtle, RDF-XML oder JSON-LD Dateien bereitgestellt. Viele Organisationen, kulturelle Einrichtungen, Museen, Bibliotheken und Archive stellen neben klassischen REST APIs wie wir sie kennengelernt haben auch Schnittstellen zum Abrufen von Linked Data bereit, bei deren Nutzung das Dateiformat im Accept-Header mit Accept: text/turtle, Accept: application/rdf+xml oder Accept: application/ld+json angefordert wird (statt Accept: text/html wie beim Web Scrapen oder Accept: application/json wie bei der Abfrage von Daten über REST APIs).
Um Linked Data sinnvoll nutzen zu können, braucht ihr allerdings etwas Hintergrundwissen. Als Einstieg in das Thema Linked Data (und die damit zusammenhängenden Themengebiete Semantic Web und Knowledge Graphs) empfehle ich die hervorragenden Kurse des Hasso-Plattner-Instituts zu den Themen Semantic Web Technologies und Knowledge Graphs.
11.4.4. Reguläre Ausdrücke#
Reguläre Ausdrücke (engl. Regular Expression, kurz: RegEx, RegExp) sind verallgemeinerte Suchmuster (patterns) für Zeichenketten. Mithilfe von regulären Ausdrücken können syntaktische Konstrukte so beschrieben werden, dass sie ein Computer versteht. Ein syntaktisches Konstrukt ist zum Beispiel eine Zahl zwischen 1900 und 2000, eine Telefonnummer, eine Adresse, eine URL oder auch ein bestimmtes Wort in verschiedenen Flexionsformen. Mithilfe von regulären Ausdrücken können also Texte nach bestimmten Mustern durchsucht werden, und die gefundenen Konstrukte können anschließend z.B. entfernt oder bearbeitet werden. Die meisten Programmiersprachen, darunter auch Python, stellen Funktionen bereit, welche die Verwendung von regulären Ausdrücken erlauben.
Bei der Bereinigung der extrahierten Daten sind reguläre Ausdrücke oft sehr nützlich. Deswegen lohnt es sich, sich mit dieser speziellen Sprache etwas zu beschäftigen und die Syntax zumindest in den Grundzügen zu verstehen. Als Einführung empfehle ich das Regular Expressions HOWTO in den Python-Dokumentationsseiten, und für einen schnellen Überblick über die Syntax empfehle ich dieses Cheatsheet, und für fortgeschrittene Themen empfehle ich regular-expressions.info. Regex-Suchmuster könnt ihr auch online testen, zum Beispiel auf der Seite https://regex101.com/.
Wir betrachten im Folgenden zwei typische Anwendungsfälle für reguläre Ausdrücke in Web Scraping Projekten.
Anwendungsbeispiel 1: Suche nach bestimmten Mustern in den Daten
In einer der letzten Übungsaufgaben solltet ihr mithilfe der Methode .str.contains() überprüfen, ob die von der Seite Pinterest extrahierten Kommentare die Zeichenkette “cute” enthalten. Die Methode akzeptiert laut den Pandas Dokumentationsseiten als Argument eine “character sequence or regular expression”. Anstatt nur nach dem Wort “cute” zu suchen, könntet ihr einen regulären Ausdruck formulieren, der nach verschiedenen Varianten des Wortes und nach Synonymen sucht:
# comments_df["comment"].str.contains("(cuti?e)|(sweet(ie)?)")
Verständnisfrage
Welche Wörter werden mit diesem Suchmuster gefunden?
Wird auch die Zeichenkette “sweeti” gefunden?
Probiert es aus: Fügt das Suchmuster und einen Beispieltext auf https://regex101.com/ ein.
Anwendungsbeispiel 2: Dateinamen vor dem Speichern bearbeiten
Bisher haben wir Metadaten immer genauso, wie sie sind, als Dateinamen verwendet. Das ist aber nicht immer möglich oder gewünscht. Dateinamen können mithilfe von regulären Ausdrücken und der Funktion sub() aus dem Modul re aus der Python-Standardbibliothek bearbeitet werden. Die Funktion sub() tauscht alle Sequenzen in einem String, die einem gesuchten Muster entsprechen, gegen einen neuen String aus. Die Funktion nimmt einen regulären Ausdruck, einen String, gegen den die gefundenen Sequenzen ausgetauscht werden sollen, und einen String, in dem gesucht werden soll, als Argumente an. Ein Beispiel:
import re
title = "Arizona sun. [volume]_19550121.txt"
title = re.sub("\\. \\[volume\\]", "", title) # Zusatz [volume] entfernen
title = re.sub(" ", "_", title) # Leerzeichen durch Unterstriche ersetzen
title
'Arizona_sun_19550121.txt'
Für weitere Funktionen zur Arbeit mit regulären Ausdrücken schaut in die Dokumentationsseiten zum Modul re.
11.4.5. Fehler, Ausnahmen und Ausnahmebehandlung#
In Python gibt es verschiedene Arten von Fehlern: zum einen Syntaxfehler (syntax errors), die verhindern, dass Code überhaupt erst ausgeführt werden kann, und zum anderen Ausnahmen (exceptions), also Fehler, die dazu führen, dass die Ausführung des Codes abgebrochen und eine Fehlermeldung angezeigt wird. Bisher haben wir immer umgangssprachlich gesagt, dass eine Fehlermeldung “angezeigt” wird. Ganz korrekt würde man aber eigentlich sagen, dass eine Ausnahme “geworfen” wird. Eine Liste der Ausnahmen, welche die Python Standard Library definiert und die beim Ausführen von Python-Code geworfen werden können, findet sich hier: https://docs.python.org/3/library/exceptions.html#bltin-exceptions.
Grundsätzlich sollte euer Code vorbeugend mit möglichen Fehlerquellen umgehen: Netzwerkanfragen können immer auch scheitern, und diese Fälle sollten immer registriert und aufgefangen werden. Und auch die Daten, die ihr extrahiert, können unterschiedlich strukturiert sein, und unterschiedliche Weiterverarbeitungsschritte erfordern. Bei der Wahl des Dateinamens solltet ihr bedenken, dass Dateinamen zum Beispiel nicht unendlich lang sein dürfen, oder dass Schrägstriche in den Dateinamen beim Schreiben der Dateien fälschlich als Dateipfade interpretiert werden können (das haben wir im Zusammenhang mit der LOC API bemerkt). In beiden Fällen würde jeweils eine Ausnahme geworfen werden und die Ausführung des Codes würde abbrechen. Ihr solltet euren Code also immer vorausschauend schreiben. Im Beispiel mit den Dateinamen könnten vorausschauend Metadaten für die Dateinamen ausgewählt werden, welche immer dieselbe Form haben und somit immer gültig sind, oder indem die Dateinamen vor dem Schreiben der Dateien vereinheitlicht werden. Aber nicht immer kann im Voraus abgeschätzt werden, welche Art von ungültigen Werten auftreten können. Für diesen Fall gibt es in Python spezielle Anweisungen, die erlauben, bestimmte Ausnahmen gezielt abzufangen und so ein vorzeitiges Beenden des Programms zu verhindern: sogenannte try/except-Anweisungen.
Try/except-Anweisungen haben die allgemeine Form:

Fig. 11.13 Try/Except-Anweisungen in der allgemeinen Form#
Der Code im except-Zweig wird dabei nur dann ausgeführt, wenn beim Ausführen des Codes im try-Zweig eine Ausnahme geworfen wird. Diese einfache try/except-Anweisung kann um weitere Zweige ergänzt werden. Eine komplexere try-except-Struktur könnte ungefähr so aussehen:
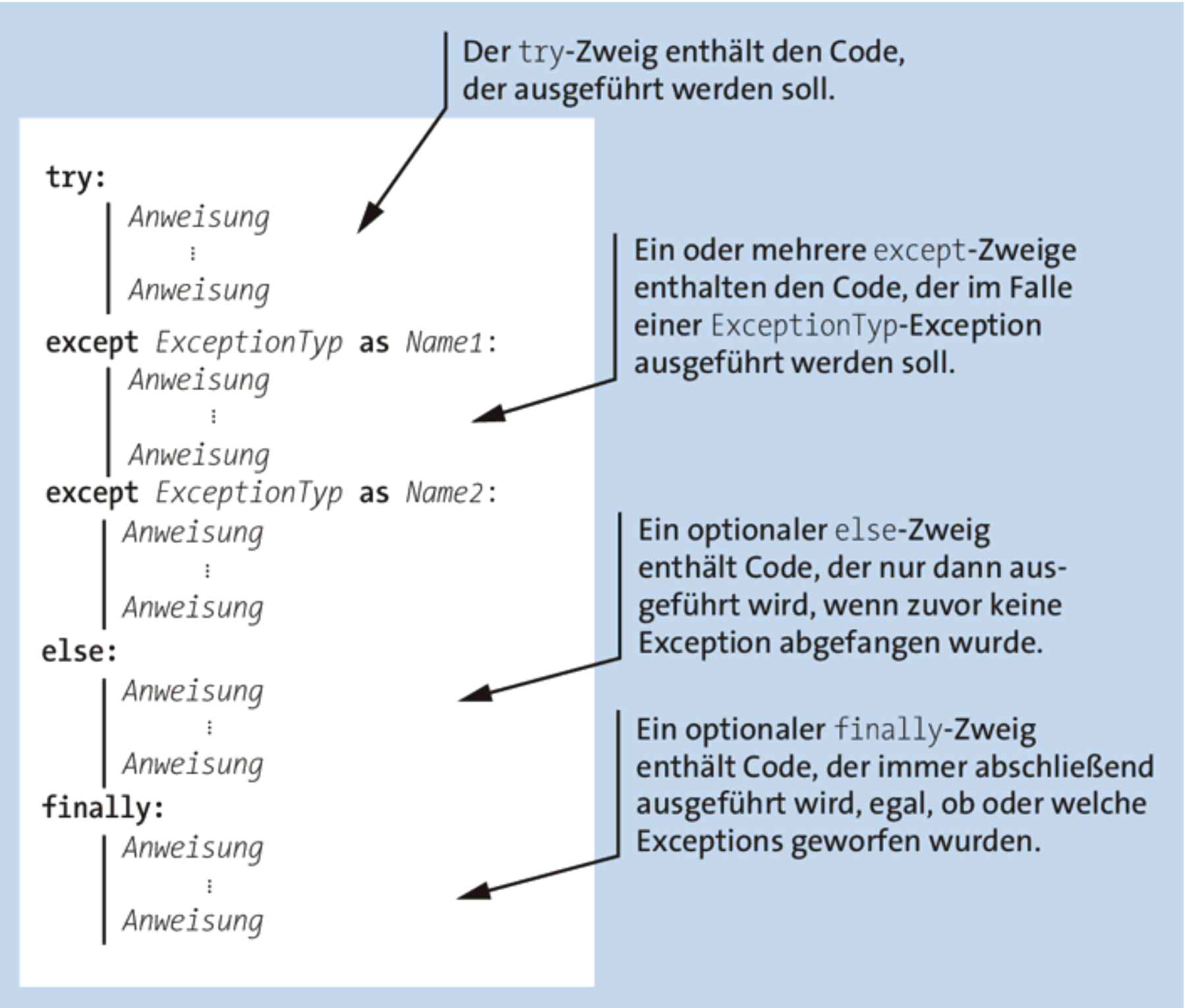
Fig. 11.14 Schaubild: try/except-Anweisung mit mehreren Zweigen. Adaptiert von Ernesti und Kaiser (2020).#
Der folgende Beispielcode fängt Ausnahmen, die durch das Paket requests geworfen werden, ab, indem es die Ausnahme loggt. Beim Auftreten einer Ausnahme wird die Ausführung jedoch nicht abgebrochen, sondern es wird None zurückgegeben und danach fährt der Code mit der nächsten URL fort.
import requests
import logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
# Funktion, die getestet werden soll
def get_page(url, timeout=10):
try:
response = requests.get(url, timeout=timeout)
# Wenn der Statuscode im 400er oder 500er Bereich liegt, wird eine Requests Exception (HTTPError) geworfen.
response.raise_for_status()
return response.text
except requests.exceptions.RequestException as e:
logger.warning(f"Exception of type {type(e).__name__} occurred while fetching {url}", exc_info=True)
return None
req_url = "https://example.com"
for i in range(10):
response = get_page(f"{req_url}/page={i}")
if response is None:
# Dieser Fall muss hier behandelt werden
Note
Ausnahmen sollten immer so spezifisch wie möglich abgefangen werden. Prinzipiell ist es möglich, mit except Exception alle möglichen Ausnahmen gleichzeitig abzufangen, aber das ist laut Ernesti und Kaiser (sowie den allermeisten seriösen Quellen zufolge) fast nie sinnvoll und kein guter Stil.
Neben dem Abfangen von Ausnahmen gibt es in Python auch die Möglichkeit, eigene Ausnahmen zu werfen oder Ausnahmen an den aufrufenden Code weiterzugeben. Dazu wird das Schlüsselwort raise verwendet:
import requests
import logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
def get_page(url, timeout=10):
try:
response = requests.get(url, timeout=timeout)
# Wirft HTTPError bei Statuscodes 4xx / 5xx
response.raise_for_status()
return response.text
except requests.exceptions.RequestException as e:
logger.warning(f"Exception of type {type(e).__name__} occurred while fetching {url}", exc_info=True)
# Ausnahme an aufrufenden Code weiterreichen
raise
req_url = "https://example.com"
for i in range(10):
get_page(f"{req_url}/page={i}")
Note
Verständnisfragen:
Überlegt euch ein Szenario, in dem es sinnvoll sein könnte, beim Scheitern einer Anfrage None zurückzugeben und die nächste Seite zu scrapen.
Überlegt euch ein Szenario, in dem dieses Vorgehen problematisch ist, und es besser ist, wenn die Ausführung des Codes komplett abbricht.
Was sollte in den beiden Szenarien mit den URLs der Seiten geschehen, die nicht erfolgreich gescraped werden konnten?
Weitere Beispiele und Erläuterungen zum Thema Ausnahmebehandlung findet ihr im erwähnten Handbuch von Ernesti und Kaiser, in diesem Beitrag von Said van de Klundert, und natürlich in den offiziellen Python-Dokumentationsseiten.
11.4.6. Logging statt print() verwenden#
Insbesondere im Zusammenhang mit Fehler- und Ausnahmebehandlung und bei Skripten mit längeren Ausführungszeiten ist es häufig unpraktisch, wenn Warnungen nur mit print() auf dem Bildschirm ausgegeben werden. Praktischer wäre es, wenn Meldungen abgestuft nach Dringlichkeit und Art und mit einer Zeitangabe versehen in einer Logdatei gespeichert würden. Um dem eigenen Webscraping-Projekt einen derartigen Logging-Mechanismus hinzuzufügen, kann das Modul logging aus der Python-Standardbibliothek verwendet werden. Die Dringlichkeitsstufen im logging-Modul sind DEBUG, INFO, WARNING, ERROR und CRITICAL und dienen dazu, verschiedene Arten von Ereignissen zu beschreiben, die beim Ausführen des Codes auftreten.
In den Python-Dokumentationsseiten findet sich dieses Beispiel, das illustriert, wie das logging-Modul ohne Setup mit den Defaulteinstellungen verwendet werden kann:
import logging
logging.warning('Watch out!') # will print a message to the console
logging.info('I told you so') # will not print anything
WARNING:root:Watch out!
Das Problem dabei ist, dass nur Nachrichten mit dem Level WARNING ausgegeben werden, und dass diese direkt im Notebook ausgegeben werden und nicht in eine Logdatei geschrieben werden. Um eine Logdatei anzulegen und einzustellen, welche Dringlichkeitsstufe dort registriert werden soll, kann dieser Code verwendet werden, der ebenfalls in leicht adaptierter Form den Dokumentationsseiten entnommen ist:
import logging
logger = logging.getLogger(__name__)
logging.basicConfig(filename='example.log', encoding='utf-8', format='%(asctime)s %(levelname)s:%(message)s', level=logging.DEBUG)
logger.debug('This message should go to the log file')
logger.info('So should this')
logger.warning('And this, too')
logger.error('And non-ASCII stuff, too, like Øresund and Malmö')
Weitere Informationen zum Logging findet ihr hier:
11.4.7. Verschiedene Lösungen vergleichen#
In der Sitzung “Fortsetzung BeautifulSoup” haben wir versucht, verschiedene Lösungen auf eine recht naive Art zu vergleichen, indem wir einfach die Zeit, die beim einmaligen Ausführen einer Codezelle verstrichen ist, gemessen haben. Die Ausführungszeit kann aber beim wiederholten Ausführen desselben Codeblocks schwanken. Um eine etwas genauere Messung zu erhalten, kann anstelle von %%time %timeit verwendet werden, um die durchschnittliche Ausführungszeit einer Funktion bei mehreren wiederholten Aufrufen zu messen. Als Beispiel messen wir die Ausführungszeit der is_even()-Funktion aus Abchnitt 4.1:
def is_even(i):
"""
Input: i, a positive int
Returns True if i is even, otherwise False
"""
return i%2 == 0
%timeit is_even(10)
74.7 ns ± 0.0569 ns per loop (mean ± std. dev. of 7 runs, 10,000,000 loops each)
Angenommen, wir haben eine weitere Lösung für dasselbe Problem gefunden: Anstatt den Modulo-Operator zu verwenden, um zu bestimmen, ob die angegebene Zahl durch 2 teilbar ist, reduzieren wir die Zahl in einer Schleife immer weiter um 2, bis 0 erreicht ist (oder nicht). Dann können wir die durchschnittliche Ausführungszeit dieser Lösung mit der ersten vergleichen:
def is_even_v2(i):
"""
Input: i, a positive int
Returns True if i is even, otherwise False
"""
while i > 1:
i -= 2
return i == 0
%timeit is_even_v2(10)
244 ns ± 1.96 ns per loop (mean ± std. dev. of 7 runs, 1,000,000 loops each)
Der Vergleich der durchschnittlichen Ausführungszeit kann einen ersten Anhaltspunkt geben, welche der zwei Lösungen effizienter im Hinblick auf die Ausführungszeit ist.
Gerade beim Web Scrapen hängt die Ausführungszeit aber auch von Faktoren ab, die wir gar nicht kontrollieren können und die sich von Ausführung zu Ausführung unterscheiden können, zum Beispiel der Zeit, die der Server braucht, um eine Antwort zu senden. Deswegen reicht der Vergleich der durchschnittlichen Ausführungszeit oft alleine nicht aus. Die gemessene Laufzeit lässt beispielsweise keine Rückschlüsse darüber zu, wie sich die Laufzeit entwickelt, wenn nicht nur 10 oder 20 sondern 100, 1000 oder 10000 Anfragen gestellt und die extrahierten Daten verarbeitet werden sollen. Mit einer theoretischen Analyse der Laufzeit, also der Bestimmung der sogenannten “Laufzeitkomplexität” des Codes, kann untersucht werden, wie sich die Laufzeit bei einer immer größer werdenden Anzahl von Eingabe-URLs unabhängig von äußeren Einflüssen wie dem Rate Limit oder der Antwortzeit des Servers entwickelt. Einen leicht verständlichen Einstieg in das Thema findet ihr hier. Einen fundierten Einstieg findet ihr hier. Sehr, sehr kurz gefasst: Die theoretische Laufzeit wird anhand der Anzahl der grundlegenden Operationen in dem Code verglichen. Bei jedem Funktionsaufruf der Funktion is_even() finden beispielsweise nur zwei Operationen statt: Der Ausdruck i % 2 == 0 berechnet den Rest der Division von i durch 2 und prüft das Ergebnis auf Wertgleichheit mit dem Wert 0. Es findet also die gleiche Anzahl an Operationen statt, egal welche Zahl für i eingesetzt wird. Eine solche Laufzeit wird auch konstante Laufzeit genannt. Beim Aufruf der Funktion is_even_v2() finden jedoch mehrere Operationen statt, wobei die Anzahl der Operationen steigt, wenn i größer ist, weil die while-Schleife für größere Zahlen mehr Durchläufe braucht, bis i < 1 ist. Eine solche Laufzeit wird lineare Laufzeit genannt, weil die Anzahl der Operationen proportional mit der Eingabegröße wächst. Die theoretische Laufzeit der Funktion is_even() deswegen deutlich geringer als die der Funktion is_even_v2(). In der formalen Syntax zur Beschreibung von Laufzeitkomlexität (der sogenannten O-Notation) wird die konstante Laufzeit der Funktion is_even() als O(1) notiert und die lineare Laufzeit der Funktion is_even_v2() als O(n).
11.4.8. Code testen#
Im Laufe des Semesters haben wir immer die Ausführung des Codes mit print() überwacht und den Output am Ende manuell überprüft. Dabei haben wir z.B. überprüft, ob der Code die erwartete Anzahl von Ergebnissen geliefert hat, welche Datentypen Funktionen zurückgeben, wenn beim Scrapen keine HTML-Elemente gefunden werden und was in diesem Fall passiert, und wir haben stichprobenartig untersucht, ob die Ergebnisse auch vollständig erscheinen. Diese Überprüfungsschritte werden bei größeren Softwareprojekten in Form von Tests formalisiert. Wenn ihr Code für eine Publikation oder eine Abschlussarbeit schreibt, solltet ihr auf jeden Fall Tests hinzufügen und euch eigenständig etwas in das Thema einlesen.
Das Ziel von Softwaretests ist es, zu überprüfen, ob sich der Code sowohl im Normalfall als auch im Fehlerfall wie erwartet verhält. Um das zu überprüfen, kann versucht werden, bewusst ein falsches, ungewolltes Verhalten des Programms herbeizuführen, also zum Beispiel einen unkontrollierten Abbruch mit einer Fehlermeldung, oder unvollständig extrahierte oder andere als die erwarteten Daten. Wenn solch ein Verhalten auftritt, dann liegt sehr wahrscheinlich ein Defekt (umgangssprachlich “Fehler”, siehe dazu mein Kommentar im Abschnitt 4.1.9) im Code vor, der dann ausgebessert werden muss. Die Tests sollen dabei für eine möglichst breite Abdeckung sorgen, es sollen also alle wichtigen Fälle und Pfade, die bei der Ausführung durchlaufen werden können, einmal getestet werden (also z.B. jede Verzweigung bei einer if-else-Verzweigung, die wichtigsten HTTP-Statuscodes, Grenzwerte und Wertebereiche, die eine Variable annehmen kann).
Web Scraper zu testen ist aber nicht ganz so einfach, weil in der Regel in einem ersten Schritt mithilfe sogenannter “Unit Tests” alle Teile des Codes separat getestet werden und es dabei hinderlich ist, wenn beim Testen tatsächlich Netzwerkanfragen gestellt werden. Denn wenn aus einem Test heraus Anfragen gestellt werden, dann würden wir ja überprüfen, ob das requests-Paket sich wie erwartet verhält, und nicht z.B. die Funktion, die wir selbst geschrieben haben, aus der heraus die Anfragen gestellt werden. Außerdem würden wir den Server mit unnötigen Testanfragen zusätzlich belasten. Deswegen müssen HTTP-Anfragen in Unit Tests oft “gemockt” werden, das heißt, es muss ein Ersatzobjekt definiert werden, das den Teil des Codes, der die Anfrage stellt, in dem Test ersetzt. Solche Tests können mithilfe der beiden Pakete pytest und pytest-mock geschrieben werden. Beide Pakete müssen dazu zunächst installiert werden, aber nur pytest muss importiert werden. Tests werden gewöhnlich nicht in Jupyter Notebooks geschrieben, sondern in Dateien mit der Dateiendung .py. Eine auf das Notwendigste reduzierte Version eines solchen Tests könnte so aussehen:
# Datei scraper.py
import requests
import logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
# Funktion, die getestet werden soll
def get_page(url, timeout):
try:
response = requests.get(url, timeout=timeout)
# Wenn der Statuscode im 400er oder 500er Bereich liegt, wird eine Requests Exception (HTTPError) geworfen.
response.raise_for_status()
return response.text
except requests.exceptions.RequestException as e:
logger.warning(f"Exception of type {type(e).__name__} occurred while fetching {url}", exc_info=True)
return None
# Datei test_scraper.py
import pytest
import requests
import scraper # Scraper-Modul (Datei scraper.py) importieren
# Erste Testfunktion, die den Normalfall testet, bei dem die Anfrage erfolgreich ist, keine Ausnahme geworfen wird und die Funktion den Inhalt der Antwort als HTML-String zurückgibt
# Der Name der Datei, in der die Funktion get_page() definiert wird, steht dann vor get_page in der Testfunktion, also z.B. name_der_datei.get_page; hier also scraper.get_page
def test_get_page(mocker):
html_content = "<html><body><h1>Das ist ein Test</h1></body></html>"
mock_response = mocker.Mock()
mock_response.text = html_content
mock_response.raise_for_status.return_value = None
mock_get = mocker.patch("scraper.requests.get", return_value=mock_response)
result = scraper.get_page("https://www.example.com", timeout=4)
# Überprüfen, ob die Funktion die HTML-Datei als String zurückgibt, wenn die Anfrage erfolgreich ist
assert result == html_content
# Überprüfen, ob die Funktion wirklich requests.get aufgerufen hat und eine Anfrage an "https://www.example.com" gestellt hat
mock_get.assert_called_once_with("https://www.example.com", timeout=4)
# Überprüfen, ob raise_for_status() aufgerufen und der HTTP Statuscode der Antwort überprüft wurde
mock_response.raise_for_status.assert_called_once()
# Zweite Testfunktion, die den Fehlerfall testet, bei dem requests.get() selbst eine RequestException auslöst, z.B. bei Netzwerkfehlern, Timeouts oder ungültiger URL wie hier im Beispiel
def test_get_page_exception(mocker):
mock_get = mocker.patch("scraper.requests.get", side_effect=requests.exceptions.RequestException())
result = scraper.get_page("some-invalid-page", timeout=4)
# Überprüfen, ob die Funktion None zurückgibt, wenn eine Exception auftritt
assert result is None
# Überprüfen, ob die Funktion versucht hat, eine Anfrage an "some-invalid-page" zu stellen
mock_get.assert_called_once_with("some-invalid-page", timeout=4)
# Dritte Testfunktion, die den Fehlerfall testet, bei dem die Anfrage zwar eine Antwort liefert, aber raise_for_status() aufgrund eines HTTP-Statuscodes im 4xx- oder 5xx-Bereich eine HTTPError-Exception auslöst
def test_get_page_http_error(mocker):
mock_response = mocker.Mock()
mock_response.raise_for_status.side_effect = requests.exceptions.HTTPError()
mocker.patch("scraper.requests.get", return_value=mock_response)
result = scraper.get_page("https://example.com", timeout=4)
# Überprüfen, ob die Funktion None zurückgebt, wenn durch raise_for_status() ein HTTP-Fehler geworfen wird
assert result is None
Die Tests werden normalerweise über die Kommandozeile mit dem Befehl pytest test_scraper.py ausgeführt (siehe dazu Abschnitt 11.4.10. “Strukturierung von Python-Projekten”). test_scraper.py ist dabei der Name der Datei, in der die Testfunktionen stehen. Wenn die Tests erfolgreich sind, steht in der Ausgabe neben dem Namen der jeweiligen Testfunktion PASSED. Nach den Unit Tests folgen meist weitere Tests, z.B. Integrationstests und Lasttests.
Einen praxisorientierten Einstieg in das Thema Softwaretests im Rahmen von Forschungsprojekten bietet die Seite https://carpentries-incubator.github.io/better-research-software/06-code-correctness.html. Die Pytest-Dokumentationsseiten finden sich unter https://docs.pytest.org/en/stable/index.html und die Pytest-mock-Dokumentationsseiten unter https://pytest-mock.readthedocs.io/en/latest/. Dieses Video illustriert, wie ein ähnlicher Test für Anfragen, die eine JSON-Antwort liefern, aussehen könnte.
11.4.9. Robuster scrapen mit requests#
Bisher haben wir mit requests immer sehr simple Anfragen gestellt. In der Praxis werden aber besonders bei größeren Projekten einige zusätzliche Einstellungen notwendig. Dazu gehören unter anderem:
Retries: Wie oft sollen bei einer gescheiterten Anfrage erneute Anfragen gestellt werden?
Timeouts: Wie lange soll auf eine Antwort des Servers gewartet werden?
Ausnahmebehandlung: Was soll bei ungültigen Statuscodes, Netzwerkfehlern oder Timeouts gemacht werden? Wie soll mit Weiterleitungen (Statuscodes im 300er Bereich) umgegangen werden?
Den Statuscode haben wir bisher mit if-Anweisungen der Art if response.status_code == 200 überprüft. Dafür bietet requests eine wesentlich kürzere und robustere Schreibweise: response.raise_for_status().
Wir haben bereits im Abschnitt 8.3 im Zusammenhang mit der API der Library of Congress drei ganz grundlegende Strategien kennengelernt, wie die Anzahl der Anfragen über das Paket requests begrenzt werden kann. Dabei habt ihr auch gesehen, wie die Anzahl der Anfragen im Gesamten limitiert werden kann, wenn aus mehreren Codeabschnitten heraus Anfragen gestellt werden. Eine einfache Lösung, die mit allen drei besprochenen Strategien umsetzbar ist, ist die Definition einer generischen Funktion, über die alle Anfragen von überall im Code geleitet werden. Der folgende Code ergänzt dieses Vorgehen um weitere Aspekte: die Anfragen werden aus einer requests-Session heraus gestellt, für Statuscodes im 400er und 500er Bereich wird mit raise_for_status() automatisch eine Ausnahme geworfen, die dann im Except-Block behandelt wird, und mit dem Parameter timeout wird angegeben, wieviele Sekunden auf eine Antwort vom Server gewartet werden soll, bevor eine Ausnahme geworfen wird:
import logging
import requests
from ratelimit import limits, sleep_and_retry
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
PERIOD = 60
CALLS_PER_PERIOD = 80
TIMEOUT = 10 # Alternativ kann mit TIMEOUT = (3, 8) zwischen Verbindungsaufbau (connect timeout) und Lesen der Antwort (read timeout) unterschieden werden
USER_AGENT = f"mein-forschungsprojekt (https://github.com/meine-seite/mein-forschungsprojekt) requests/{requests.__version__}"
@sleep_and_retry
@limits(calls=CALLS_PER_PERIOD, period=PERIOD)
def get_page(session, url, timeout=TIMEOUT):
try:
response = session.get(url, timeout=timeout)
logger.info(f"Fetched {url} with status code: {response.status_code}")
response.raise_for_status()
return response
except requests.exceptions.RequestException as e:
logger.warning(f"Request for {url} failed with exception: {e}")
return None
base_url = "https://www.loc.gov/pictures/search/?q=suffragettes&fo=json"
num_pages = 14
req_session = requests.Session()
req_session.headers.update({"User-Agent": USER_AGENT})
for page in range(1, num_pages + 1):
req_url = f"{base_url}&sp={page}"
response = get_page(req_session, req_url)
if response is None:
# Diesen Fall hier abfangen
# Rest des Codes, s. Lösung zum Übungsblatt 9
Diesen Code erkennt ihr vielleicht wieder: Es handelt sich um eine modifizierte Version der Musterlösung zum Übungsblatt 9.
Neben dem Rate Limit selbst wollt ihr aber oft auch kontrollieren, wie oft beim Scheitern einer Anfrage versucht werden soll, eine Anfrage erneut zu stellen, wieviele Retries es also geben soll, und wie lange vor jedem Retry gewartet werden soll. Das folgende Beispiel illusriert eine Möglichkeit, wie Retries im Zusammenhang mit requests konfiguriert werden können sowie weitere Möglichkeiten, das Verhalten von requests zu steuern. Dazu wird auf das Paket urllib3 zurückgegriffen, das requests selbst unter der Motorhaube nutzt. Die verwendeten Parameter werden dabei in den Kommentaren erläutert. Beachtet aber, dass Redirects, also Weiterleitungen, auch ohne den Parameter redirect=2 durch requests standardmäßig berücksichtigt werden; mit redirect=2 wird nur die maximale Anzahl der Weiterleitungen, denen gefolgt werden soll, auf 2 begrenzt.
import logging
import requests
from requests.adapters import HTTPAdapter
from urllib3.util.retry import Retry
from ratelimit import limits, sleep_and_retry
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
# Settings
PERIOD = 60
CALLS_PER_PERIOD = 80
TOTAL_RETRIES = 5
BACKOFF_FACTOR = 0.5
STATUS_FORCELIST = (429, 500, 502, 503, 504)
TIMEOUT = 10
USER_AGENT = f"mein-forschungsprojekt (https://github.com/meine-seite/mein-forschungsprojekt) requests/{requests.__version__}"
# Funktionsdefinitionen
def setup_session(user_agent, total_retries=TOTAL_RETRIES, backoff_factor=BACKOFF_FACTOR, status_forcelist = STATUS_FORCELIST):
session = requests.Session()
retries = Retry(
total=total_retries, # Maximal fünf Retries
backoff_factor=backoff_factor, # Exponential backoff: bei jeder zusätzlichen Anfrage etwas länger warten
status_forcelist=status_forcelist, # Bei diesen Statuscodes nochmal probieren
allowed_methods=("GET",),
redirect=2, # Für Statuscodes im 300er-Bereich
respect_retry_after_header=True, # Retry-After Header in der Response beachten, falls vorhanden
raise_on_status=True, # Bei Statuscodes im Bereich 400-599 wir nach der maximalen Anzahl von Retries eine Exception geworfen
)
adapter = HTTPAdapter(max_retries=retries)
session.mount("http://", adapter) # Einstellungen für alle Requests über http verwenden
session.mount("https://", adapter) # Einstellungen für alle Requests über https verwenden
session.headers.update({"User-Agent": user_agent})
return session
@sleep_and_retry
@limits(calls=CALLS_PER_PERIOD, period=PERIOD)
def get_page(session, url, timeout=TIMEOUT):
try:
response = session.get(url, timeout=timeout)
logger.info(f"Fetched {url} with status code: {response.status_code}")
return response
except requests.exceptions.RequestException as e:
logger.warning(f"Request for {url} failed with exception: {e}")
return None
# Hauptlogik mit Aufruf der Funktionen
base_url = "https://www.loc.gov/pictures/search/?q=suffragettes&fo=json"
num_pages = 14
req_session = setup_session(USER_AGENT)
for page in range(1, num_pages + 1):
req_url = f"{base_url}&sp={page}"
response = get_page(req_session, req_url)
if response is None:
# Diesen Fall hier abfangen
# Rest des Codes
Zum Verständnis der Retry-Logik sollte erwähnt werden, dass die Retry-Logik per Default nur bei Problemen bei der Anfrage selbst (Netzwerkprobleme, Timeouts,..) ausgelöst wird. Mit status_forcelist werden deswegen explizit Statuscodes angegeben, bei denen die Retry-Logik zusätzlich ausgelöst werden soll. Der Parameter respect_retry_after_header=True bewirkt, dass wenn die Antwort vom Server den Retry-After Header verwendet, die darin angegebene Wartezeit verwendet wird statt der mit backoff_factor und ratelimit selbst festgelegten Wartezeit. Diese Variante macht schon vieles besser, aber es gibt noch einige Probleme: Die Aufrufe der Funktion get_page() werden zwar durch unsere ratelimit-Dekoratoren kontrolliert, aber die Retries erfordern keinen Aufruf der Funktion get_page(). Wenn die Anfrage bereits scheitert, bevor sie den Server erreicht, z.B. aufgrund von Netzwerkproblemen, ist das okay. Aber was, wenn Anfragen für die in unserer mit status_forcelist angegebenen Liste von HTTP-Statuscodes wiederholt werden? Dann werden bei einem Aufruf der Funktion get_page() mehrere Anfragen an den Server gesendet und das festgelegte Ratelimit wird womöglich überschritten! Zu bedenken ist auch, dass der Scraper bei einer gescheiterten Anfrage nicht abbricht, sondern nur die URL und die Ausnahme im Log vermerkt und dann mit der nächsten URL weitermacht. Im Körper der for-Schleife, aus der heraus die get_page()-Funktion aufgerufen wird, muss also der Fall berücksichtigt werden, dass die Funktion None zurückgibt, wenn eine Anfrage scheitert. Die Seiten, die nicht erfolgreich gescraped werden konnten, sollten in einem Web Scraping Projekt aber natürlich nicht einfach verschwinden, sondern dieser Fall muss untersucht und beim Verarbeiten der Daten berücksichtigt werden. Wenn die gescrapten Daten z.B. in einem Pandas Dataframe gespeichert werden, sollten Seiten, die nicht gescraped werden konnten, also beispielsweise trotzdem vorkommen, aber die entsprechende Zeile im Dataframe ist leer, oder es könnte eine weitere Spalte hinzugefügt werden, in der der Statuscode oder Grund des Scheiterns der Anfrage vermerkt wird. Es kann auch eine eigene Datei angelegt werden, in der die URLs von Seiten, die nicht gescraped werden konnten, gesammelt werden. Wenn es allerdings wichtig ist, dass alle Seiten gescraped werden, dann sollte die get_page() Funktion dagegen lieber nicht None zurückgeben, sondern es sollte mit dem Schlüsselwort raise eine eigene Ausnahme geworfen werden, damit der aufrufende Code, also unsere for-Schleife, die Informationen über die Ausnahme erhält und die Ausführung abbricht.
Note
Verständnisfragen:
Wie könnte sichergestellt werden, dass das Rate Limit auch bei Retries eingehalten wird? Lest euch dazu den folgenden Blogbeitrag durch: https://rebrowser.net/blog/python-requests-retry-the-ultimate-guide-to-handling-failed-http-requests-in-python
Schreibt die Funktion get_page() so um, dass beim Scheitern einer Anfrage mithilfe des Schlüsselworts
raiseund/oder der requests-Methode raise_for_status() eine Ausnahme geworfen wird und die Ausführung abbricht.Was bedeuten die Statuscodes 429, 500, 502, 503 und 504, für die im zweiten Codebeispiel explizite Retries implementiert wurden?
11.4.10. Versionsverwaltung nutzen#
Im Laufe des Semesters hat sich euer Ordner mit den Notebooks bestimmt mit einer Reihe Dateien der Art “uebung_9_loesung_v1.ipynb”, “uebung_9_loesung_v2.ipynb”, “uebung_9_loesung_final.ipynb” gefüllt. Klar: Wenn ihr eine alternative Lösung gefunden habt, wollt ihr diese vielleicht nicht löschen, oder ihr wollt lieber erstmal eine Sicherheitskopie anlegen, bevor ihr den Code noch einmal umschreibt. Weil das beim Coden ein häufiges Problem ist, haben sich Systeme zur sogenannten Versionsverwaltung etabliert. In der professionellen Softwareentwicklung ist die Verwendung solcher Systeme ein unverzichtbarer Standard. Eine extrem verbreitete, kostenfreie und betriebssystemübergreifende Variante ist die Kombination von Git mit GitHub. Die Git-Dokumentationsseiten definieren Versionsverwaltung wie folgt:
Was ist “Versionsverwaltung”, und warum solltest du dich dafür interessieren? Versionsverwaltung ist ein System, welches die Änderungen an einer oder einer Reihe von Dateien über die Zeit hinweg protokolliert, sodass man später auf eine bestimmte Version zurückgreifen kann. Die Dateien, die in den Beispielen in diesem Buch unter Versionsverwaltung gestellt werden, enthalten Quelltext von Software. Tatsächlich kann in der Praxis nahezu jede Art von Datei per Versionsverwaltung nachverfolgt werden. (Quelle: Git Dokumentationsseiten)
Die mithilfe von Git lokal angelegten Git Repositories (also Ordner auf dem Computer, in denen mithilfe von Git Änderungen an Dateien nachverfolgt werden) können auf Online-Plattformen wie GitHub hochgeladen werden, um sie mit anderen zu teilen oder für die private Nutzung an zentraler Stelle zu speichern. In einem GitHub-Repository kann neben dem Code und den Daten für ein Webscraping-Projekt auch eine Datei mit den Versionen der verwendeten Python Pakete und der Python-Version geteilt werden. Das ist empfehlenswert, denn so macht ihr es anderen leichter, euren Code zu reproduzieren. Eine solche Datei könnt ihr ganz einfach in Anaconda Prompt bzw. dem Terminal generieren, indem ihr die virtuelle Umgebung aktiviert und dann eingebt conda env export --no-builds > environment.yml. Diese Datei kann dann jemand anderes nutzen, um bei sich auf dem Computer mit dem Befehl conda env create -f environment.yml eine virtuelle Umgebung mit denselben Paketen zu erstellen.
Über GitHub könnt ihr auch andere Web Scraping Projekte, Python-Pakete oder einzelne Module und Funktionen, deren Einsatzmöglichkeiten ihr verstehen wollt, suchen. Gebt dazu in der Suchmaske einfach ein Stichwort, den Namen eines Pakets oder der Funktion ein, wenn ihr diesen kennt, und filtert die Ergebnisse anschließend nach der Programmiersprache. Bevor ihr euch dazu entscheidet, für eine Seite einen Web Scraper zu schreiben, könnt ihr auch erst einmal auf GitHub suchen, ob es vielleicht bereits einen Web Scraper für die Seite gibt. Aber Vorsicht! Bevor ihr fremden Code ausprobiert, lest euch den Abschnitt “Sicher scrapen” durch und trefft ggf. Vorsichtsmaßnahmen. Allgemein gilt: Wenn ein GitHub Repository viele Maintainer:innen hat und die letzten Änderungen (Commits) erst wenige Tage, Wochen oder Monate alt sind, dann handelt es sich meist um vertrauenswürdigen Code. Ein weiterer Anhaltspunkt sind die Meldungen unter dem Tab “Issues” in einem GitHub Repository. Hier findet ihr Berichte über Fehler, fehlende Features oder Probleme beim Verwenden des Codes in verschiedenen Ausführungsumgebungen.
Einen ausführlichen Einstieg in das Thema Versionsverwaltung mit Git und GitHub bietet der Kurs Let’s Git - Versionsverwaltung und OpenSource des Hasso-Plattner-Instituts.
11.4.11. Strukturierung von Python-Projekten#
Bisher habt ihr Code immer in Jupyter Notebooks geschrieben und ausgeführt. Aber wenn ihr euch auf GitHub oder woanders auf die Suche nach fremdem Code macht, dann begegnen euch häufig auch Pythonskripte mit der Dateiendung .py und größere Projekte, die aus mehreren .py, .ipynb oder anderen Dateien bestehen. Das kann verwirrend sein. Wenn euer Webscraping Projekt komplexer wird und nicht mehr nur aus einem Jupyter Notebook, sondern noch aus Input- und Output-Dateien oder weiteren Skripten besteht, fragt ihr euch vielleicht, wie ihr die verschiedenen Dateien am besten organisieren solltet. Wir schauen uns deswegen in der letzten Stunde ein paar Beispiele an.
Ein wichtiges Vorwissen, um mit Python-Skripten, also Dateien mit der Dateiendung .py, zu arbeiten, ist, wie man den Code in solchen Dateien ausführen kann. Grundsätzlich ist der einfachste Weg, um ein Pythonskript auszuführen, die Eingabe des Befehls python name_der_datei.py in der Kommandozeile bzw. dem Terminal. Die Kommandozeile bzw. das Terminal kann auch im Jupyterlab oder in einem sogenannten Code-Editor (-> Schaubild Python Code ausführen im Kapitel 2.1 auf der Kurswebsite) aufgerufen werden. Um eine Datei auszuführen, muss entweder erst mit dem Befehl cd pfad/zum/verzeichnis in das Verzeichnis gewechselt werden, in dem das Python-Skript liegt, oder es muss beim Ausführen zusätzlich der Pfad zur Datei angegeben werden, also python pfad/zum/verzeichnis/name_der_datei.py. Manchmal begegnet man aber auch Dateien mit der Dateiendung .py, die nicht primär als Skripte zum Ausführen im Terminal gedacht sind, sondern die für den Import in andere Python-Skripte gedacht sind (-> Kapitel 4.2 auf der Kurswebsite). Manchmal, aber nicht immer, kann man ein solches für den Import gedachtes Skript daran erkennen, dass im selben Verzeichnis noch eine Datei mit dem Namen __init__.py liegt. Um so eine Datei auszuführen, muss die zusätzliche Option (auch “Flag” genannt) -m beim Ausführen mit angegeben werden, und das Verzeichnis, in dem sich die Datei befindet, kann mit der Notation name_des_verzeichnisses.name_der_datei angegeben werden. Der vollständige Befehl lautet dann python -m name_des_verzeichnisses.name_der_datei.
Zum Nachlesen empfehle ich Kapitel 24: “Module Packages” und 25: “Module Odds and Ends” in Martin Lutz (2025), Learning Python. Darin findet ihr auch eine sehr gute Erläuterung zur Verwendung des Idioms if __name__ == "__main__", das euch begegnen wird, wenn ihr nach Pythonskripte von anderen sucht. Grundsätzlich wird dieses Konstrukt immer dann verwendet, wenn ermöglicht werden soll, dass der Code sowohl in anderen Dateien importiert werden kann, als auch in der Kommandozeile ausgeführt werden kann.
11.4.12. Webscraping-Projekte mit mehreren Datenquellen#
Wenn ihr für ein Projekt nicht nur die Daten von einer, sondern von mehreren Seiten scrapen wollt und das Scrapen mehrere Schritte erfordert, wird euer Code schnell unübersichtlich und das Ausführen in einem Jupyter Notebook wird unpraktisch: Sehr langer Output wird in Jupyterlab abgekürzt dargestellt, was ein Debuggen erschwert, und wenn Codezellen manuell ausgeführt werden sollen, muss sehr darauf geachtet werden, dass die Reihenfolge eingehalten und keine Codezelle vergessen wird. Für größere Web Scraping-Projekte mit mehreren Datenquellen und verschiedenen Verarbeitungsschritten lohnt sich deswegen der Umstieg von Jupyter Notebooks auf Pythonskripte, damit nicht alles in einer Datei steht. Neben einer solchen Modularisierung profitieren größere Webscraping-Projekte auch von zusätzlichen Mechanismen wie dem bereits besprochenen Logging, einer ordentlichen Ausnahmebehandlung, aber auch Caching und, bei mehreren Datenquellen, einer nicht-sequentiellen Ausführung des Codes. Was bedeutet das? Wenn Daten von zwei verschiedenen Websites sequentiell gescraped werden, heißt das, dass erst die Daten von der einen Website und dann die Daten von der zweiten Website gescraped werden. Wenn beim Scrapen großzügige Wartezeiten eingebaut werden, um die Rate Limits der Webseite einzuhalten, dann ist das ziemlich ineffizient, weil viel Wartezeit anfällt, während der nichts passiert. Bei einer nicht-sequentiellen Ausführung ist das anders. Die sogenannte nebenläufige Ausführung von Code ermöglicht, die anfallende Wartezeit auszunutzen, indem während der Wartezeit bereits andere Verarbeitungsschritte erfolgen und zum Beispiel Anfragen an die zweite Website gestellt werden. Bei einer parallelen Ausführung von Code werden die Anfragen an verschiedene Webseiten sogar gleichzeitig ausgeführt.
Eine ordentliche Implementierung von Caching und nicht-sequentielle Programmausführung erfordert aber fortgeschrittene Programmierkenntnisse. Es gibt deswegen einige Pakete, die Programmbausteine unter anderem für nebenläufige Netzwerkanfragen und Caching bereitstellen. Zwei solche Pakete sind in Python Scrapy und Prefect.
Zum Einstieg in Scrapy empfehle ich das Scrapy-Tutorial, in dem die Zitate von der euch bereits bekannten Seite quotes.toscrape.com extrahiert werden, und für den Einstieg in Prefect empfehle ich das Beispiel aus den Prefect Dokumentationsseiten, welches illustriert, wie Prefect für Webscraping verwendet werden kann.
11.4.13. Sicher Scrapen#
Die Anforderungen an Sicherheit und Anonymität können sich von Web Scraping Projekt zu Web Scraping Projekt unterscheiden. Ein paar Dinge sind aber allgemein empfehlenswert:
Achtet nach Möglichkeit darauf, dass in eurer Anfrage-URL https statt http steht.
Falls ihr euch auf einer Webseite anmelden müsst, um Inhalte scrapen zu können, solltet ihr immer ein Profil speziell für diesen Zweck erstellen. Gebt niemals sensible Passwörter in den automatisierten Chrome Browser ein.
Seid außerdem vorsichtig, wenn ihr verschiedene Tipps online lest: Bevor ihr einfach komplexen Code von Stackoverflow oder einem ähnlichen Forum kopiert, recherchiert, ob es nicht vielleicht einen einfacheren Weg gibt, um euer Problem zu lösen. Denn wenn ihr gar nicht versteht, was ihr gerade macht, könnt ihr auch nicht abschätzen, welche Risiken das kopierte Vorgehen mit sich bringt, und welche Sicherheitsvorkehrungen die andere Person vielleicht vorher getroffen hat.
Dasselbe gilt für Code von KI-Bots, Code aus GitHub Repositories und sogar für Python Pakete: Schaut am besten immer selbst erst den Code an, bevor ihr ihn ausführt, und recherchiert erst einmal, ob der Code aktuell ist, ob es sich um ein bekanntes und gut gepflegtes Paket handelt oder ob es ein acht Jahre altes Hobbyprojekt von einer Einzelperson ist. Diese Informationen findet ihr meist über die Projekt-Links auf der Seite des Pakets auf pypi.org oder direkt auf GitHub.
Beachtet an dieser Stelle auch noch einmal den Sicherheitshinweis aus der ersten Stunde: Code, den ChatGPT oder eine andere LLM-Anwendung generiert hat zu kopieren und auf dem eigenen Rechner auszuführen, ohne zu verstehen, was der Code macht, birgt erhebliche Sicherheitsrisiken, besonders dann, wenn aus dem Code heraus Webseiten aufgerufen werden. Dazu zählt nicht nur die Tatsache, dass Code, der aus Internetforen kopiert oder von LLMs generiert wird, oft sicherheitsrelevante Schwachstellen aufweist, sondern auch Risiken durch neuere Angriffsstrategien wie das sogenannte AI Slopsquatting, data-, model- und tool poisoning sowie indirect prompt injections. Solche Angriffe zählen zu “Supply Chain Attacks”, die in den letzten Jahren massiv angestiegen sind und insbesondere Open Source Projekte im Python- und JavaScript Ökosystem betreffen (siehe dazu z.B. diesen Blogbeitrag).
Bösartiger Code findet sich auch sehr häufig in Paketen, die sehr ähnlich benannt sind wie populäre Bibliotheken und häufige Schreibfehler abbilden (beatifulsoup4, beautifulsoup o.Ä. statt beautifulsoup4). Diese Form der Angriffe wird deswegen auch Typosquatting genannt. Achtet deswegen immer darauf, dass ihr beim Installieren die Paketnamen richtig schreibt.
Es empfiehlt sich außerdem, beim Web Scrapen ganz allgemein einen Useraccount auf eurem Computer zu verwenden, der keine Administratorrechte hat. Falls doch etwas schief gehen sollte, ist dadurch der Schaden zumindest begrenzt.
Wenn ihr ganz sicher gehen wollt, verwendet eine virtuelle Maschine zum Scrapen. Virtuelle Maschinen können z.B. mithilfe spezialisierter Software wie UTM für MacOS erstellt werden.
In manchen der Praxisbeispiele wurden Passwörter und Usernamen zu Demonstrationszwecken in den Code geschrieben. Beachtet aber die Hinweise dazu und macht das nicht so nach. Zugangsdaten sollten niemals direkt in den Code geschrieben werden.
Mit dem Aktivitätsmonitor (MacOS) bzw. Ressourcenmonitor (Windows) könnt ihr nach dem Scrapen überprüfen, ob alle Python- und Chromedriverprozesse korrekt beendet wurden.
Je nach Web Scraping Projekt kann es empfehlenswert sein, die eigene IP-Adresse mithilfe von VPN oder Proxy zu verstecken. Allerdings ist das ethisch und rechtlich eine schwierige Sache: Wir haben beispielsweise bereits besprochen, dass man sich strafbar machen kann, wenn man beim Web Scraping blockiert wird und anstatt seinen Web Scraper robots.txt-konform umzuschreiben einfach seine IP-Adresse versteckt. Hier ist also Vorsicht und Eigenrecherche geboten.
11.4.14. Effizienter Scrapen mit Sitemaps#
Eine Sitemap ist eine strukturierte Übersicht über alle Unterseiten einer Website. Webseitenbetreiber:innen stellen Sitemaps zur Verfügung, damit beim Crawlen der Seite durch Web Crawler verschiedener Suchmaschinen alle Unterseiten einfach gefunden werden können. Je nach gesuchten Daten können Sitemaps auch beim Web Scraping eingesetzt werden, um effizienter eine Liste von zu scrapenden Unterseiten zusammenzustellen. Sitemaps werden meist im XML-Format bereitgestellt, das heißt, dass zur Suche in solchen Sitemaps ebenfalls XPath verwendet werden kann. Sitemaps sind oft unter der Adresse www.beispielwebseite.com/sitemap.xml erreichbar, aber anders als bei der robots.txt gibt es noch einige andere typische Adressen. Eine Übersicht über solche typischen Sitemap-Adressen findet ihr hier. Manche Webseitenbetreiber:innen verlinken die Sitemap zudem in der robots.txt. Dies ist zum Beispiel bei der Website realpython.com der Fall. Die Sitemap ist hier unter https://realpython.com/robots.txt verlinkt und hat die Adresse https://realpython.com/sitemap.xml. Die Sitemap selbst sieht so aus:
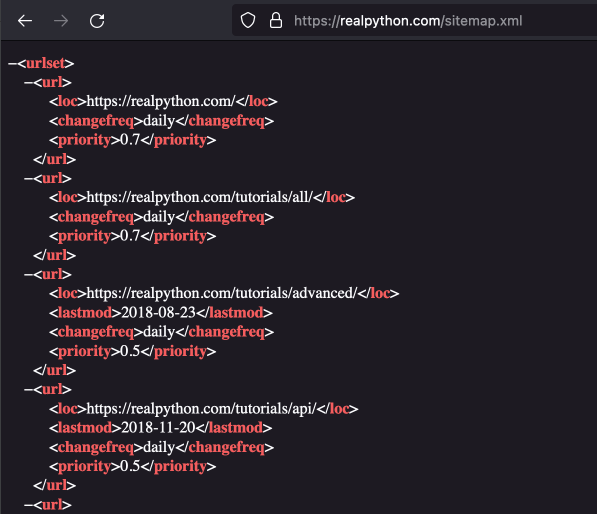
Fig. 11.15 Sitemap der Website realpython.com#
11.4.15. Wo steht nochmal…#
F-Strings: Kapitel 8.2.3
List Comprehension: Kapitel 8.2.3
Daten schreiben: Kapitel 8.2.3 und Kapitel 10.1.3
Rate Limiting: Kapitel 8.3.5
XPath: Kapitel 9.3.3 und Kapitel 9.3.5
11.4.16. Don’t do this…#
Zum Schluss möchte ich euch noch eine kleine Empfehlung mit auf den Weg geben: Nicht immer ist Web Scraping wirklich die schnellste und effizienteste Lösung für euer Problem. Es macht wahrscheinlich mehr Spaß, Code zu schreiben, als direkt die Aufgabe anzugehen, aber wenn ihr unbedingt eine Deadline einhalten müsst, dann ist es natürlich auch okay, ein Web Scraping Projekt abzubrechen und eure Aufgabe einfach manuell zu lösen. Also in diesem Sinne:

Fig. 11.16 Don’t do this… Quelle: Kevin Sahin 2022#
11.4.17. Quellen#
Peter Ernesti, Johannes und Kaiser. Python 3: Ausnahmebehandlung. 2020. URL: https://openbook.rheinwerk-verlag.de/python/22_001.html.
Ognian Mikov. How to Find the Sitemap of a Website. 2021. URL: https://seocrawl.com/en/how-to-find-a-sitemap/.
Ryan Mitchell. Webscraping with Python. Collecting More Data from the Modern Web. O'Reilley, Farnham et al., 2018.
Jonathan Mondaut. Take Advantage of Sitemaps for Efficient Web Scraping: A Comprehensive Guide. 2023. URL: https://medium.com/@jonathanmondaut/take-advantage-of-sitemaps-for-efficient-web-scraping-a-comprehensive-guide-c35c6efe52d3.
Kenneth Reitz. Requests Documentation: Errors and Exceptions. 2023. URL: https://requests.readthedocs.io/en/latest/user/quickstart/?highlight=cookie#errors-and-exceptions.
Kevin Sahin. Web Scraping Using Selenium and Python. 2022. URL: https://www.scrapingbee.com/blog/selenium-python/.
Carsten Sinz. Vorlesung "Algorithmen und Datenstrukturen". 03: Korrektheit von Algorithmen, Asymptotische Laufzeiten. 2019. URL: https://youtu.be/7vUGHpbQABk?si=8FsyfJkPNQTjhZv-.
Baiju Muthukadan. Selenium with Python. Waits. 2024. URL: https://selenium-python.readthedocs.io/waits.html.
Python 3.11.3 Documentation. Built-in Exceptions. URL: https://docs.python.org/3/library/exceptions.html#bltin-exceptions.
Python 3.11.3 Documentation. Compound Statements: The Try Statement. URL: https://docs.python.org/3/reference/compound_stmts.html#the-try-statement.
Python 3.11.3 Documentation. Errors and Exceptions. URL: https://docs.python.org/3/tutorial/errors.html.
Said van de Klundert. Python Exceptions: An Introduction. URL: https://realpython.com/python-exceptions/.
Selenium 4 Documentation. Browser Options: pageLoadStrategy. 2022. URL: https://www.selenium.dev/documentation/webdriver/drivers/options/#pageloadstrategy.
Selenium 4.10 Documentation. Waits. 2023. URL: https://www.selenium.dev/documentation/webdriver/waits/.
W3Docs. How to Find an Element by CSS Class Name with XPath. 2023. URL: https://www.w3docs.com/snippets/css/how-to-find-an-element-by-css-class-name-with-xpath.html.