9.1. Statische vs. Dynamische Webseiten?#
Die Unterscheidung zwischen “statischen” und “dynamischen” Webseiten ist für uns vor allem heuristisch wichtig, weil wir vor dem Web Scraping wissen müssen, wann und wie beim Aufruf einer Webseite welche Inhalte geladen werden, und dazu müssen wir zunächst verstehen, wann und wie HTML-Dokumente und Inhalte “gerendert”, also erzeugt und dargestellt werden. Die Abgrenzung von dynamischen und statischen Webseiten ist aber nicht ganz einfach und in der Praxis wird meistens eher von statischen und dynamischen Inhalten gesprochen oder es wird nach den konkreten Verfahren unterschieden, mit denen Webseiten und Inhalte erstellt und dargestellt werden. Solche Verfahren heißen zum Beispiel “Server-Side Rendering”, “Static Site Generation”, “Incremental Static Regeneration”, “Automatic Static Optimization” oder “Client-Side Rendering”. Wie genau diese Verfahren für eine konkrete Webseite umgesetzt werden, hängt wiederum davon ab, ob es sich um eine sogenante “Single Page Application” oder eine “Multi Page Application” handelt, und davon, welche Frameworks bei der Entwicklung der Website eingesetzt werden. Solche Frameworks heißen z.B. Next.js, Angular, React, Django oder Flask und jedes Framework allein wäre schon Stoff für ein gesamtes Semester.
Ihr seht: Das Thema ist sehr komplex und in diesem kurzen Abschnitt können wir uns nur sehr sehr oberflächlich das notwendige Praxiswissen erarbeiten, um Web Scraping-Strategien verstehen zu können, die für komplexere Webseitenarten und -inhalte konzipiert wurden. Wir widmen uns zunächst den beiden Begriffen “statisch” und “dynamisch”, denn das sind Begriffe, die gerne in Webscraping-Tutorials verwendet werden, und an denen wir uns auch bisher orientiert haben.
9.1.1. Statische Webseiten#
A static site is one that returns the same hard coded content from the server whenever a particular resource is requested. So for example if you have a page about a product at /static/myproduct1.html, this same page will be returned to every user. If you add another similar product to your site you will need to add another page (e.g. myproduct2.html) and so on.
Quelle: MDN Contributors 2023
Etwas simpler definiert Alexander Bazo von der Uni Regensburg statische Webseiten:
Einzelne Dokumente liegen im HTML-Format an zentraler Stelle bereit und werden vollständig an den Client übertragen, um dort angezeigt zu werden.
Quelle: Alexander Bazo 2020
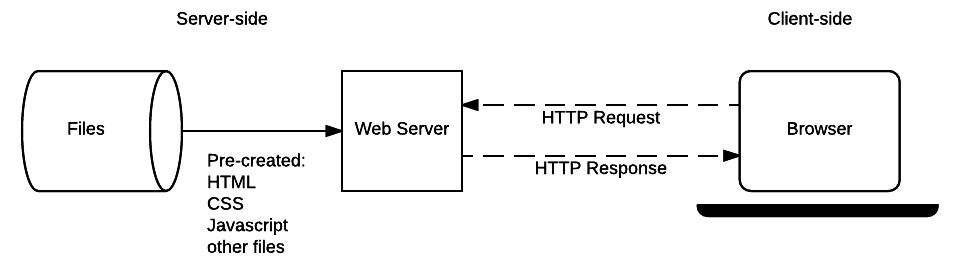
Fig. 9.1 Schaubild Statische Webseite. Bild: MDN Contributors 2023#
Formell definiert ist eine statische Website also dadurch definiert, dass alle Unterseiten schon gerendert sind, bevor sie auf den Webserver hochgeladen und bereitgestellt werden. Diese Art von Webseiten kennen wir bereits: quotes.toscrape.com und diese Kurswebsite sind Beispiele. Für die Unterseiten einer solchen statischen Website werden vorab, bevor die Website auf dem Server hochgeladen wird, einzelne HTML-Dokumente erstellt, eins für jede Unterseite, die dann auf den Server hochgeladen werden. Beim Seitenaufruf wird das HTML-Dokument für die jeweils aufgerufene Seite unverändert an den Client geschickt und, wenn der Client ein Browser ist, im Browser dargestellt. Solche Webseiten können wir ganz einfach mit requests und BeautifulSoup scrapen.
Allerdings gibt es auch auf statischen Webseiten Inhalte, die wir nicht mithilfe von requests und BeautifulSoup scrapen können, zum Beispiel die Suchergebnisse, die euch bei der Verwendung der Suchmaske auf dieser Website angezeigt werden. Die Suche auf dieser Kurswebsite ist nämlich mithilfe von JavaScript implementiert. Wenn ihr euch die Seite https://lipogg.github.io/webscraping-mit-python/search.html?q=selenium in den Entwicklertools anseht, dann sieht die Seite zwar erst einmal nach einem ganz normalen HTML-Dokument aus: Die Suchergebnisse findet ihr als Liste im div-Element mit der id “search-results”.
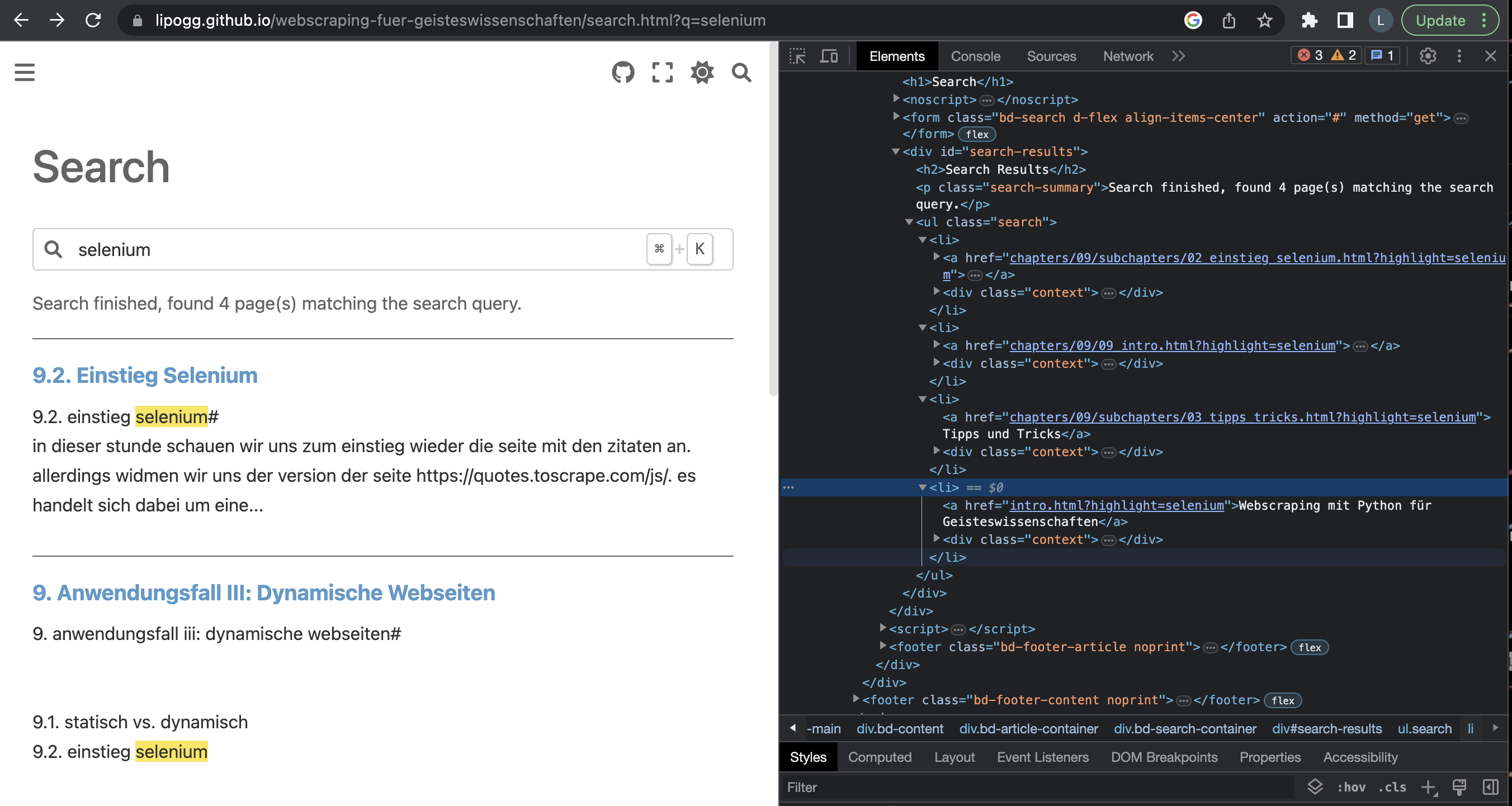
Fig. 9.2 Suche auf der Kurswebsite mit aktiviertem JavaScript#
Aber wenn ihr versucht, die Seite mit den Suchergebnissen mithilfe von requests und BeautifulSoup zu scrapen, dann bekommt ihr stattdessen ein HTML-Dokument zurück, das nicht die Suchergebnisse, sondern eine Meldung “Please activate JavaScript to enable the search functionality” enthält.
import requests
from bs4 import BeautifulSoup
URL = "https://lipogg.github.io/webscraping-mit-python/search.html?q=selenium"
page = requests.get(URL)
soup = BeautifulSoup(page.content, "html.parser")
soup.select('.bd-search-container')
[<div class="bd-search-container">
<h1>Search</h1>
<noscript>
<div class="admonition error">
<p class="admonition-title">Error</p>
<p>Please activate JavaScript to enable the search functionality.</p>
</div>
</noscript>
<form action="#" class="bd-search d-flex align-items-center" method="get">
<i class="fa-solid fa-magnifying-glass"></i>
<input aria-label="Search this book..." autocapitalize="off" autocomplete="off" autocorrect="off" class="form-control" id="search-input" name="q" placeholder="Search this book..." spellcheck="false" type="search"/>
<span class="search-button__kbd-shortcut"><kbd class="kbd-shortcut__modifier">Ctrl</kbd>+<kbd>K</kbd></span>
</form>
<div id="search-results"></div>
</div>]
Dasselbe Dokument wird euch auch im Browser angezeigt, wenn ihr JavaScript im Browser deaktiviert.
Note
JavaScript im Browser deaktivieren
Um JavaScript zu deaktivieren, geht ihr so vor: Öffnet die Seite -> View -> Developer Tools -> Tastenkombination Ctrl + Shift + P bzw. auf dem Mac Cmd + Shift + P -> Disable JavaScript eingeben und Enter drücken. Um JavaScript später wieder einzuschalten, befolgt ihr dieselben Schritte und sucht nach “Enable JavaScript”.
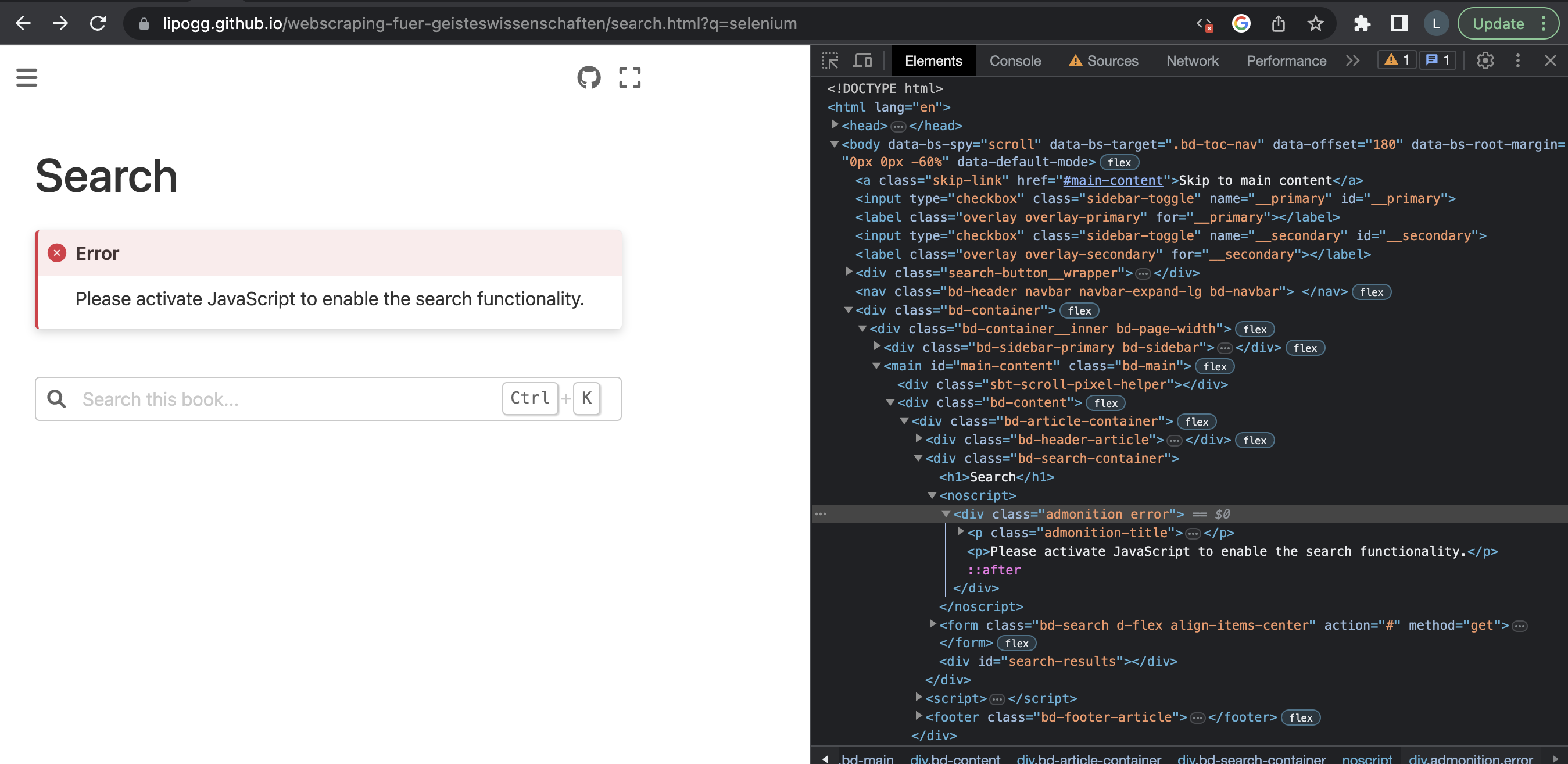
Fig. 9.3 Suche auf der Kurswebsite mit deaktiviertem JavaScript#
Obwohl wir es bei der Kurswebsite mit einer statisch generierten Website zu tun haben, können wir diese spezielle Unterseite also nicht mithilfe von requests und BeautifulSoup scrapen, weil für die Darstellung der Inhalte JavaScript verwendet wird. Das Beispiel zeigt: Anders als man vielleicht alltagssprachlich vermuten würde, liegt der Unterschied zwischen “statischen” und “dynamischen” Webseiten also nicht darin, ob die Inhalte interaktiv sind, sondern darin, wie genau und wann sie erstellt und dargestellt werden.
9.1.2. Dynamische Webseiten#
A dynamic site is one that can generate and return content based on the specific request URL and data (rather than always returning the same hard-coded file for a particular URL). Using the example of a product site, the server would store product “data” in a database rather than individual HTML files. When receiving an HTTP GET Request for a product, the server determines the product ID, fetches the data from the database, and then constructs the HTML page for the response by inserting the data into an HTML template.
Quelle: MDN Contributors 2023
Definition von Alexander Bazo von der Uni Regensburg:
Der Inhalt dynamischer Websites wird durch Aktionen auf Client und Server beeinflusst. Das Dokument, das vom Client gerendert wird, liegt nicht zwangsläufig genauso auch als HTML-Dokument auf dem Server.
Quelle: Alexander Bazo 2020
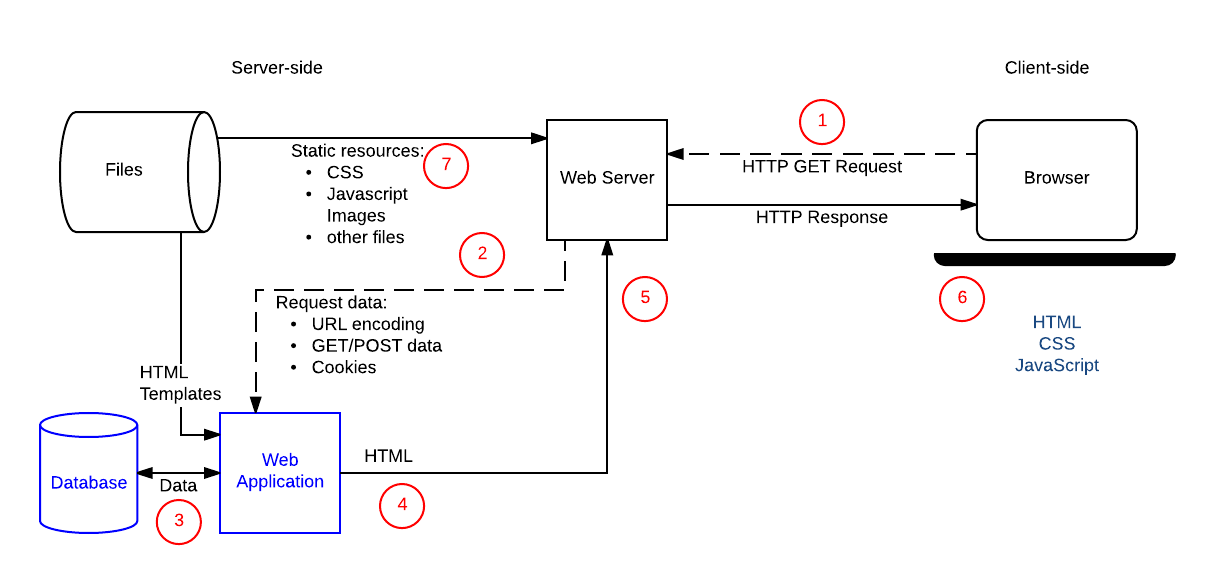
Fig. 9.4 Schaubild Dynamische Webseite. Bild: MDN Contributors 2023#
Eine dynamische Website ist dagegen formell gesprochen eine Website, die erst dann erstellt und dargestellt wird, wenn sie aufgerufen wird. Wie bereits eingangs erwähnt gibt es verschiedene Verfahren, um Websites “dynamisch” zu erstellen und darzustellen: Eine Website kann im Gesamten auf dem Server oder auf dem Client gerendert werden, oder es wird ein Teil einer Webseite auf dem Server gerendert, und der Rest auf dem Client.
Wird beim Aufruf der Webseite das komplette HTML-Dokument mit allen Inhalten auf dem Server generiert, heißt das: die HTML-Dokumente werden erst dann erstellt, wenn die Seite aufgerufen wird, und zwar auf dem Server. Erst, wenn die Webseite komplett fertig gerendert ist, wird sie an den Client, zum Beispiel einen Browser, geschickt. Dieses Rendering-Verfahren wird beispielsweise standardmäßig für WordPress-Seiten verwendet. Wenn das HTML-Dokument komplett gerendert mit allen Inhalten an den Client geschickt wird, können wir zum Scrapen solcher Seiten im Regelfall requests und BeautifulSoup verwenden, denn dann erhalten wir ein fertiges HTML-Dokument, genau wie beim Scrapen statischer Webseiten. Ein Beispiel ist diese Wordpress-Seite https://minimalistbaker.com. Der Aufruf der Seite mit deaktiviertem JavaScript zeigt, dass für die Darstellung der Überblicksseite tatsächlich kein JavaScript benötigt wird, denn alle Inhalte werden komplett geladen:
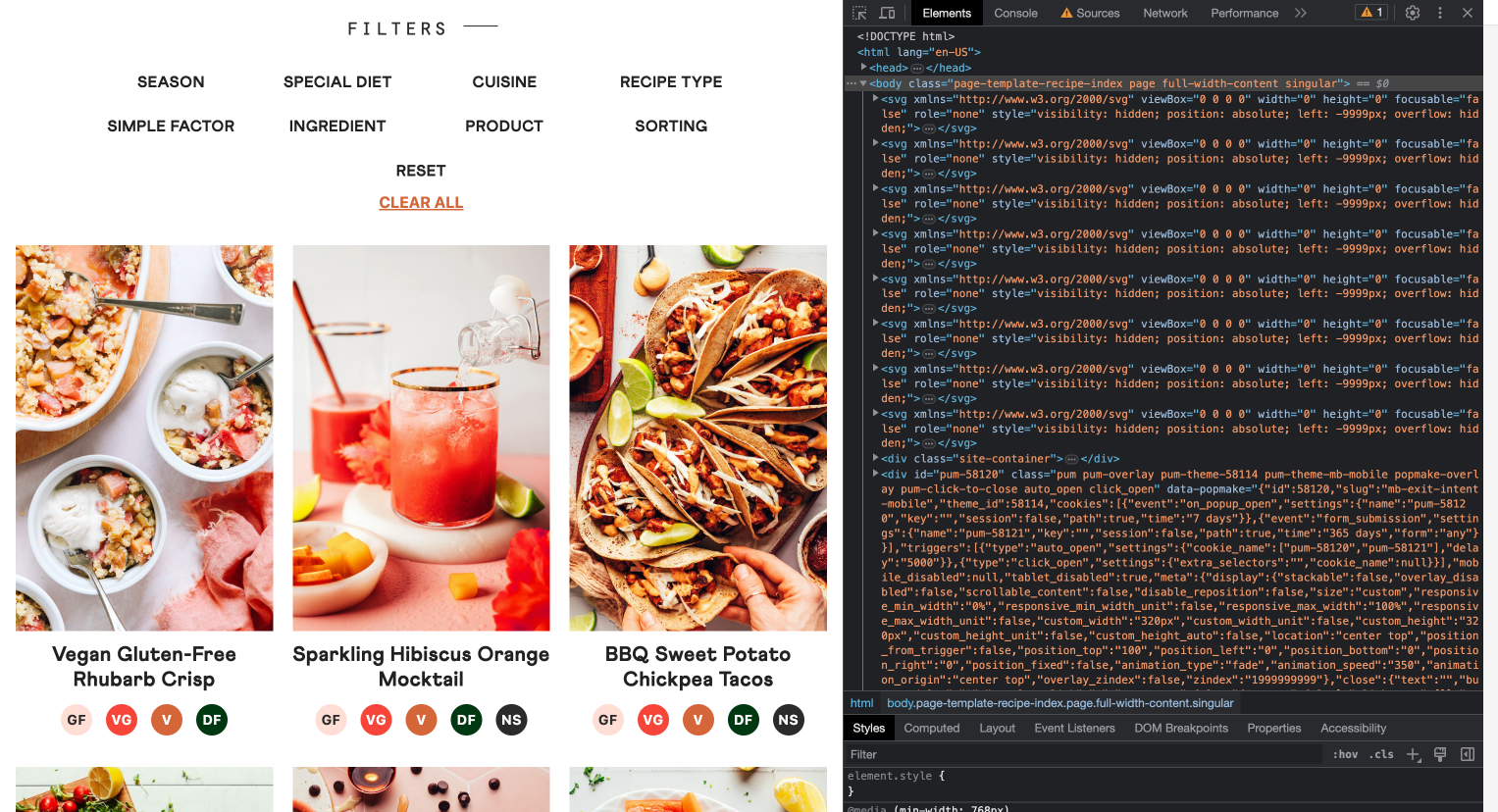
Fig. 9.5 Beispiel-Wordpressseite mit deaktiviertem JavaScript.#
Die HTTP-GET-Anfrage liefert also ein komplett gerendertes HTML-Dokument, das wir mit BeautifulSoup durchsuchen können:
URL = "https://minimalistbaker.com/recipe-index/?fwp_paged=2"
page = requests.get(URL)
soup = BeautifulSoup(page.content, "html.parser")
soup.select('.post-summary__title')
[<h3 class="post-summary__title"><a href="https://minimalistbaker.com/vegan-chocolate-cheesecake-cups/">No-Bake Vegan Chocolate Cheesecake Cups (5 Minutes!)</a></h3>,
<h3 class="post-summary__title"><a href="https://minimalistbaker.com/cucumber-lime-agua-fresca/">Cucumber Lime Agua Fresca</a></h3>,
<h3 class="post-summary__title"><a href="https://minimalistbaker.com/creamy-mocha-chia-pudding/">Creamy Mocha Chia Pudding</a></h3>,
<h3 class="post-summary__title"><a href="https://minimalistbaker.com/easy-raspberry-compote/">Easy Raspberry Compote (Naturally Sweetened)</a></h3>,
<h3 class="post-summary__title"><a href="https://minimalistbaker.com/creamy-tuscan-shrimp-pasta-dairy-free/">Creamy Tuscan Shrimp Pasta (Dairy-Free)</a></h3>,
<h3 class="post-summary__title"><a href="https://minimalistbaker.com/gluten-free-lemon-poppy-seed-muffins-vegan/">Gluten-Free Lemon Poppy Seed Muffins (Vegan)</a></h3>,
<h3 class="post-summary__title"><a href="https://minimalistbaker.com/italian-lentil-soup-zuppa-di-lenticchie/">Italian Lentil Soup (Zuppa di Lenticchie)</a></h3>,
<h3 class="post-summary__title"><a href="https://minimalistbaker.com/chocolate-pot-de-creme-sweet-potato/">Chocolate Pot de Crème (with a Secret Ingredient!)</a></h3>,
<h3 class="post-summary__title"><a href="https://minimalistbaker.com/banana-chocolate-pecan-muffins-vegan-gf/">1-Bowl Banana Chocolate Pecan Muffins (Vegan + GF)</a></h3>,
<h3 class="post-summary__title"><a href="https://minimalistbaker.com/creamy-vegan-white-bean-chili/">Creamy Vegan White Bean Chili</a></h3>,
<h3 class="post-summary__title"><a href="https://minimalistbaker.com/easy-winter-fruit-salad/">Easy Winter Fruit Salad (1 Bowl!)</a></h3>,
<h3 class="post-summary__title"><a href="https://minimalistbaker.com/chocolate-tahini-caramels-no-candy-thermometer/">Chocolate Tahini Caramels (No Candy Thermometer!)</a></h3>,
<h3 class="post-summary__title"><a href="https://minimalistbaker.com/chocolate-pecan-shortbread-cookies-vegan-gf/">Chocolate Pecan Shortbread Cookies (Vegan + GF)</a></h3>,
<h3 class="post-summary__title"><a href="https://minimalistbaker.com/garlic-herb-roasted-delicata-squash/">Garlic & Herb Breaded Delicata Squash</a></h3>,
<h3 class="post-summary__title"><a href="https://minimalistbaker.com/cranberry-orange-scones-vegan-gf/">1-Bowl Cranberry Orange Scones (Vegan + GF)</a></h3>,
<h3 class="post-summary__title"><a href="https://minimalistbaker.com/easy-gluten-free-cornbread-1-bowl/">Easy Gluten-Free Cornbread (1 Bowl!)</a></h3>,
<h3 class="post-summary__title"><a href="https://minimalistbaker.com/1-pot-spicy-pumpkin-tomato-soup/">1-Pot Spicy Pumpkin Tomato Soup</a></h3>,
<h3 class="post-summary__title"><a href="https://minimalistbaker.com/cozy-curry-noodle-soup-thai-inspired/">Cozy Curry Noodle Soup (Thai-Inspired)</a></h3>,
<h3 class="post-summary__title"><a href="https://minimalistbaker.com/fluffy-pumpkin-oat-cookies/">Fluffy Pumpkin Oat Cookies (1 Bowl!)</a></h3>,
<h3 class="post-summary__title"><a href="https://minimalistbaker.com/vegan-pumpkin-spice-frosting/">Vegan Pumpkin Spice Buttercream Frosting</a></h3>]
Solche Webseiten sind formell gesprochen auch “dynamisch”, aber da sie bereits auf dem Server gerendert werden, und nicht erst im Client, können wir die bereits bekannte Webscraping-Strategie mit requests und BeautifulSoup darauf anwenden.
Es kommt aber häufig vor, dass dynamisch erstellte Webseiten nicht nur auf dem Server, sondern auch auf dem Client, also im Browser, gerendert werden. Beim Aufruf solcher Webseiten wird zum Beispiel als erstes nur das HTML-Grundgerüst der Seite ohne Inhalte gerendert. Die HTTP-Anfrage beim Aufruf der Seite liefert also ein HTML-Dokument, das nur das Grundgerüst der Seite enthält. Alle weiteren Inhalte werden dann mithilfe von JavaScript über eine spezielle Schnittstelle, die DOM, in das HTML-Gerüst eingefügt. Der Seiteninhalt kann dann mit demselben und ähnlichen Verfahren fortlaufend dynamisch verändert werden, je nachdem, wie ein:e Nutzer:in die Webseite verwendet. So ungefähr wird die YouTube-Startseite geladen. Wenn wir JavaScript im Browser ausschalten, wird uns nur das HTML-Grundgerüst angezeigt. Die HTML-Elemente haben passenderweise die IDs “home-page-skeleton” oder “home-container-skeleton”:
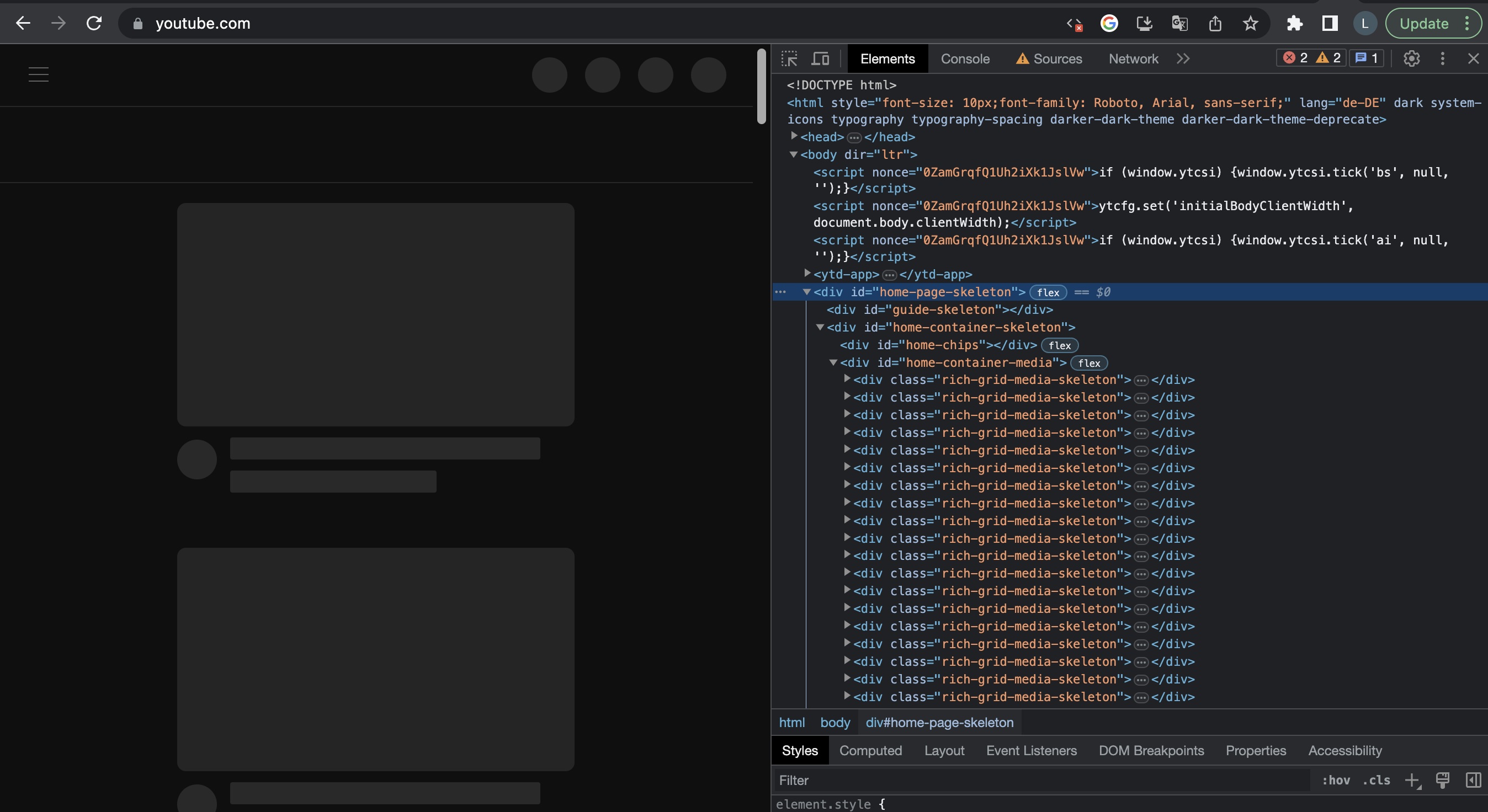
Fig. 9.6 YouTube-Startseite mit deaktiviertem JavaScript#
In diesem Fall können requests und BeautifulSoup nicht verwendet werden, weil die Anfrage nur das “Skelett” der Webseite liefert:
URL = "https://www.youtube.com/"
page = requests.get(URL)
soup = BeautifulSoup(page.content, "html.parser")
# soup.find("div", id="home-page-skeleton")
In der Praxis werden fast immer verschiedene Rendering-Verfahren kombiniert, und verschiedene Unterseiten oder auch verschiedene Inhalte auf derselben Seite können mit verschiedenen Rendering-verfahren erstellt und dargestellt werden. Die genauen Rendering-Verfahren zu identifizieren, mit denen eine Website gerendert wird, ist für uns aber auch gar nicht unbedingt notwendig. Im Fall der statischen Kurswebsite ist es für uns zum Beispiel ganz irrelevant, dass bei der Darstellung der Suchergebnisseite JavaScript verwendet wird, wenn wir uns für Inhalte auf den anderen Seiten interessieren. Für uns zählt am Ende nur, wie die konkreten Inhalte, die wir von der Webseite extrahieren wollen, erstellt und dargestellt werden, und das findet man meist mithilfe der Entwickler-Tools und ein bisschen Ausprobieren heraus.
Als Faustformel könnt ihr euch an diesem Punkt merken: Wenn für die Inhalte, die ihr scrapen wollt, JavaScript zur Darstellung verwendet wird, dann könnt ihr die Inhalte nicht allein mit requests und BeautifulSoup scrapen.
Es gibt daneben aber auch dynamische Inhalte, die nicht mit JavaScript dargestellt werden, und die ihr zwar mit requests und BeautifulSoup extrahieren könnt, allerdings muss dabei oft das Vorgehen etwas angepasst werden. Zwei Beispiele schauen wir uns im Folgenden an.
Die Seite https://readthedocs.org/search/ verwendet zum Beispiel für die Implementierung der Suche Elasticsearch, wodurch bei der Suche die Datenbank direkt über eine RESTful API angezapft wird. JavaScript wird dabei nicht benötigt, die Suche läuft in diesem Beispiel komplett serverseitig ab. Das ist auf der Website hier ausführilch dokumentiert. Um die Ergebnisse der Suche zu extrahieren, können wir in diesem Fall einfach mit requests eine API-Anfrage mit unseren Suchbegriffen als Parameter über die Elasticsearch-API stellen. Die Abfrage-URI ist in dem Fall genau die URL, die im URL-Fenster im Browser bei der Suche nach einem Suchbegriff automatisch eingetragen wird, also zum Beispiel https://readthedocs.org/search/?q=how+to+&type=file.
URL = "https://readthedocs.org/search/?q=how+to+&type=file"
page = requests.get(URL)
soup = BeautifulSoup(page.content, "html.parser")
# print(soup.prettify())
Anders ist es bei projekt-gutenberg.org. Auch hier ist die Suche ohne JavaScript serverseitig implementiert, aber wenn ein Suchbegriff über die Suchmaske eingegeben wird, dann ändert sich nicht bequem die URL im URL-Fenster, sondern die URL bleibt immer dieselbe, egal wonach wir suchen: https://www.projekt-gutenberg.org/info/search/search.php. Wenn wir uns den Quellcode der Webseite in den Entwicklertools ansehen, finden wir die Ergebnisse unserer Suche in einem HTML-Tabellenelement. Wenn wir jetzt aber mit requests eine Anfrage für diese URL stellen, dann bekommen wir ein anderes HTML-Dokument geliefert, das die Tabelle mit den Ergebnissen nicht enthält. Das ist auch nicht erstaunlich: Wir haben dem Server ja gar nicht mitgeteilt, wonach wir suchen. Der Network-Tab in den Entwicklertools verrät uns, wie wir in diesem Fall vorgehen können: Wenn ein Suchbegriff in die Suchmaske einegegeben wird, dann wird eine HTTP POST (!) Anfrage gestellt, keine GET-Anfrage. Im Header steht als Anfrage-URL https://www.projekt-gutenberg.org/info/search/search.php.
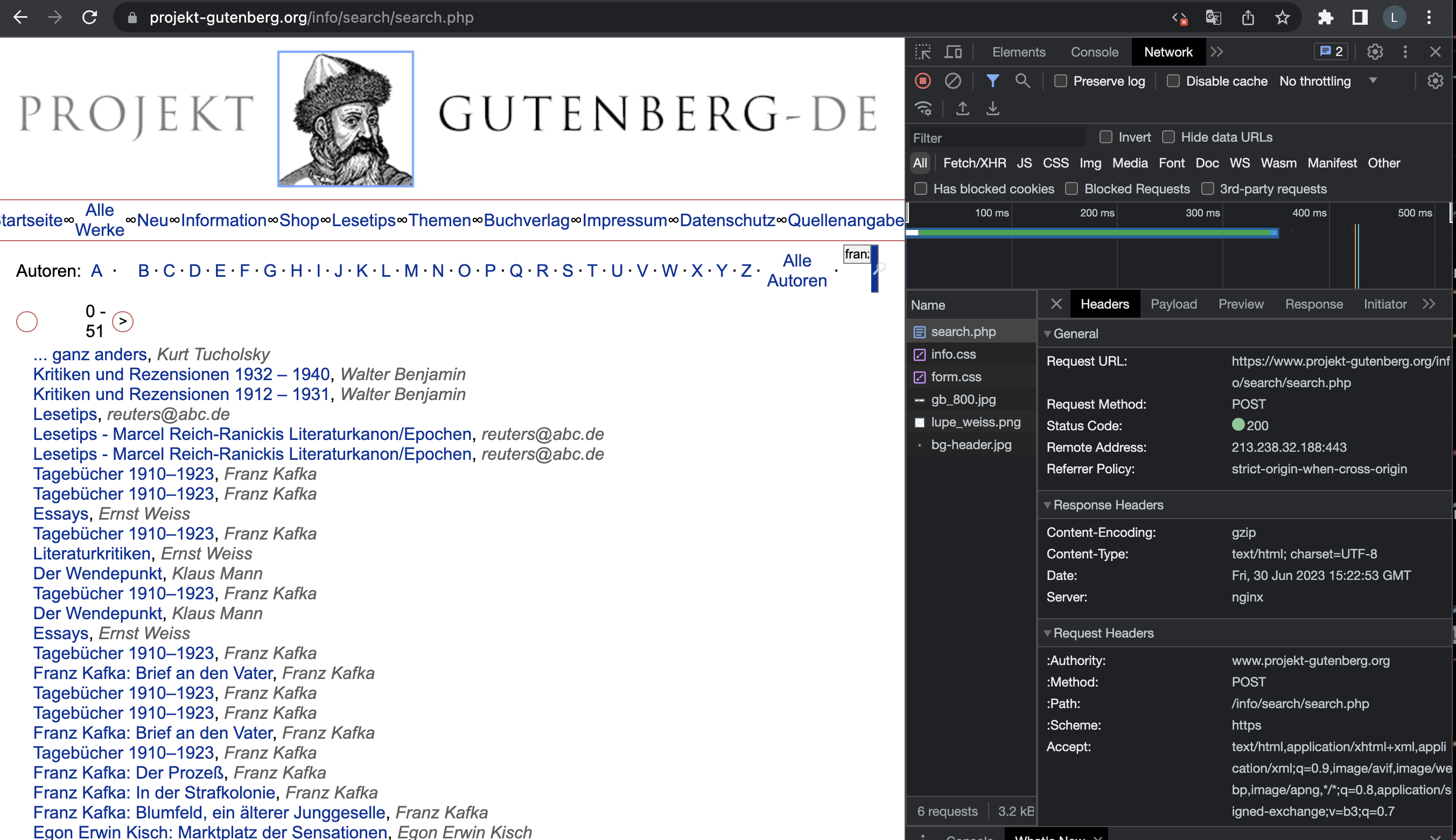
Fig. 9.7 HTTP-Anfrage bei der Suche über projekt-gutenberg.org#
Aber es wird zusätzlich ein “Payload” bei der Anfrage übermittelt, nämlich im Beispiel unten “searchstring=franz+kafka&search=suchen”.
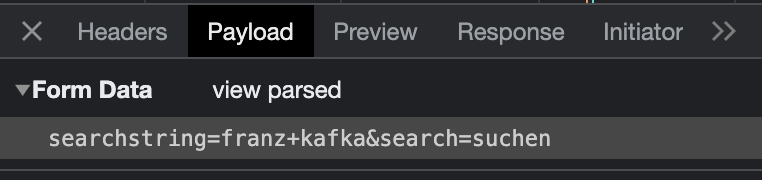
Fig. 9.8 “Payload” bei der HTTP-Anfrage#
Diese Parameter müssen wir der POST-Anfrage mit angeben. Der Python-Code sieht demnach als Beispiel für eine Suche nach Franz Kafka auf projekt-gutenberg.org so aus:
# Serverseitige Suche mit PHP: HTTP-POST-Anfrage
import requests
URL= "https://www.projekt-gutenberg.org/info/search/search.php"
params = {'searchstring':'franz+kafka', 'search':'suchen'}
page = requests.post(URL, params)
soup = BeautifulSoup(page.content, "html.parser")
# print(soup.prettify())
Die beiden Beispiele zeigen, dass dynamische Inhalte nicht immer gleich JavaScript voraussetzen. Wenn eure Anfrage mit requests also nicht erfolgreich ist, dann liegt das nicht immer gleich daran, dass JavaScript verwendet wird. Sondern oftmals müsst ihr die Anfrage einfach etwas anders stellen. Wie genau, das könnt ihr herausfinden, indem ihr die Anfragen im Netzwerk-Tab in den Browser-Entwicklertools untersucht.
9.1.3. Gängige Missverständnisse#
Interaktivität = JavaScript?
In unserem Schaubild im Kapitel “Einstieg Webscraping” ist der Anwendungsbereich von JavaScript als “Verhalten und Interaktion” beschrieben. Interaktive Elemente gibt es aber auch ohne die Verwendung von JavaScript: Das haben wir gerade eben an den Beispielen zur serverseitigen Suche auf readthedocs.org und projekt-gutenberg.org gesehen.
JavaScript = Kein BeautifulSoup?
Ein weiteres weit verbreitetes Missverständnis ist, dass JavaScript nur dazu verwendet wird, um Inhalte dynamisch zu generieren. Auf der Seite projekt-gutenberg.org wird JavaScript beispielsweise verwendet, um ein Analysetool mit dem Namen Mamoto in die Webseite einzubinden. Das Tool dient dem Tracking von Nutzerverhalten und sammelt Statistiken zum Beispiel über Seitenaufrufe durch Nutzer:innen. Es ist aber nicht an der Darstellung der Inhalte selbst beteiligt. Also: Nur, weil ihr im Quellcode einer Webseite ein script-Element seht, heißt das noch lange nicht, dass ihr requests und BeautifulSoup nicht verwenden könnt. JavaScript wird für viele verschiedene Zwecke eingebunden.
9.1.4. Takeaways#
Ihr habt gesehen: Die Wahl der richtigen Web Scraping-Strategie entscheidet sich eigentlich nicht so richtig danach, ob eine Website nun statisch oder dynamisch ist, sondern erst einmal danach, ob JavaScript für die Darstellung der Inhalte verwendet wird, die ihr scrapen wollt. Ihr habt außerdem gesehen, dass dynamische Inhalte nicht immer JavaScript voraussetzen, und dass in manchen Fällen auch ein paar Änderungen an der HTTP-Anfrage ausreichen können, um die gewünschten dynamischen Inhalte zu erhalten. Wenn die Inhalte, die ihr scrapen wollt, aber tatsächlich mithilfe von JavaScript dargestellt werden, dann solltet ihr Selenium verwenden.
Note
Wenn ihr euch nicht sicher seid, wozu JavaScript auf einer Webseite verwendet wird, die euch interessiert, gibt es verschiedene Möglichkeiten, das herauszufinden:
JavaScript in den Entwicklertools ausschalten und die Seite ohne JavaScript neu laden. (View -> Developer Tools -> Tastenkombination Ctrl + Shift + P bzw. auf dem Mac Cmd + Shift + P -> Disable JavaScript eingeben und Enter drücken)
Seitenquelltext im Browser anzeigen lassen (View -> Developer -> View Source), den Quelltext kopieren und Chat GPT schicken mit der Frage, wozu JavaScript auf der Seite verwendet wird (geht nur, wenn der Quelltext nicht zu lang ist).
Wenn ihr euch gar nicht sicher seid, könnt ihr auch erst einmal versuchen, die Webseite mit BeautifulSoup zu scrapen. Wenn der Inhalt HTML-Elemente, die ihr sucht, leer ist, oder die Elemente erst gar nicht gefunden werden, dann handelt es sich um dynamische Inhalte.
9.1.5. Quellen#
Alexander Bazo. Vorlesung "Webanwendungen und Webserver". 2020. URL: https://www.youtube.com/watch?v=Pc35Ux0bF2U.
Charles Bouchard-Légaré. Sphinx-Users: Documentation About the Built In Search? 2022. URL: https://groups.google.com/g/sphinx-users/c/qtLQXDDHbYo.
Frank Dopatka. Vorlesung "Webbasierte Systeme". JavaScript: DOM. 2021. URL: https://www.youtube.com/watch?v=DfvbYgk0XG8.
Njoku Samson Ebere. Server Side Rendering (SSR) Vs Static Site Generation (SSG) . 2023. URL: https://dev.to/ebereplenty/server-side-rendering-ssr-vs-static-site-generation-ssg-214k.
Nicholas Mendez. Understanding Rendering in Web Apps: SPA vs MPA. 2021. URL: https://dev.to/snickdx/understanding-rendering-in-web-apps-spa-vs-mpa-49ef.
Fred Meyer. Understanding "Server-Side" and "Client-Side" in WordPress. 2023. URL: https://wpshout.com/understanding-server-side-client-side-wordpress/.
Jason Miller and Addy Osmani. Rendering on the Web: Static Rendering. 2019. URL: https://web.dev/rendering-on-the-web/#static-rendering.
Jason Miller and Addy Osmani. Rendering on the Web. 2019. URL: https://web.dev/rendering-on-the-web/.
Chrome Developers. Disable JavaScript. 2019. URL: https://developer.chrome.com/docs/devtools/javascript/disable/.
MDN Contributors. Client-Server Overview. 2023. URL: https://developer.mozilla.org/en-US/docs/Learn/Server-side/First_steps/Client-Server_overview.
Next.js. Client-Side-Rendering (CSR). 2023. URL: https://nextjs.org/docs/pages/building-your-application/rendering/client-side-rendering.
Next.js. Rendering. 2023. URL: https://nextjs.org/docs/pages/building-your-application/rendering.
10 Rendering Patterns for Web Apps. 2023. URL: https://www.youtube.com/watch?v=Dkx5ydvtpCA.