9.3. Fortsetzung Selenium#
In der letzten Woche haben wir uns angesehen, wie wir Zitate von der Seite https://quotes.toscrape.com/js/ mithilfe von Selenium scrapen können. Heute werden wir uns ein etwas fortgeschritteneres Beispiel ansehen, bei dem die Interaktion mit verschiedenen Seitenelementen notwendig wird: Wir werden Ortsangaben zu Unterkünften von https://www.airbnb.com/ scrapen, zuerst die Unterkünfte von der Startseite, danach Unterkünfte von der Seite “Tiny homes” und zuletzt Unterkünfte nur in Berlin. Mit der Airbnb-Website solltet ihr euch bereits im Rahmen des letzten Übungsblatts beschäftigt haben, wir werden aber am Anfang noch einmal die Lösung wiederholen.
Zunächst rufen wir die Website im regulären Browser auf. Welche Interaktionen sind notwendig, um an die gesuchten Daten zu gelangen? Wenn wir die Startseite aufrufen, ist standardmäßig der Tab “Icons” geöffnet. Diese Seite scrollen wir bis zum Ende herunter, um alle Inhalte zu sehen. Um “Tiny homes” anzusehen, klicken wir auf das Icon “Tiny homes” und scrollen wieder bis zum Ende der Seite herunter. Am Seitenende befindet sich diesmal ein “Show more”-Button. Wenn der Button geklickt wird, wird eine weitere Seite mit Unterkünften geöffnet. Beim Herunterscrollen dieser Seite fällt auf, dass die Inhalte auf dieser Seite beim Scrollen nachgeladen werden, bis irgendwann das Seitenende erreicht ist. Um nur Unterkünfte in Berlin anzuzeigen, muss das Suchfeld benutzt werden. All diese Schritte müssen wir simulieren, wenn wir die Ortsangaben von den Unterkünften der manuell besuchten Seiten extrahieren wollen.
Note
Achtung: Beim Scrapen komplexerer Webseiten wird der Code nicht beim ersten Mal fehlerfrei ausgeführt werden. Wird die Ausführung abbricht und eine Fehlermeldung angezeigt, dann wird die aktuelle Sitzung aber nicht mehr geschlossen. Um das Problem zu lösen gibt es zwei Möglichkeiten: Entweder, die Sitzung wird mit driver.quit() immer manuell geschlossen, wenn der Code abbricht. Oder, der ChromDriver wird als “Context Manager” verwendet, indem die Sitzung mit with webdriver.Chrome() as driver gestartet wird. Dieses Konzept habt ihr bereits im Abschnitt “8.2.3.3. Daten schreiben” kennengelernt. In diesem Kapitel wird stets die zweite Variante verwendet. Vor dem nächsten Versuch muss in beiden Fällen wieder eine neue Sitzung mit webdriver.Chrome() gestartet werden.
Note
Da sich die Airbnb-Seite sehr oft ändert, Attribute umbenannt werden, zeitweise Popup-Fenster mit zeitlich begrenzten Aktionen auftauchen und manchmal sogar die Gesamtstruktur der Webseite verändert wird, ist der Code auf dieser Seite nicht immer aktuell und ausführbar. Manchmal muss nur ein Klassenname ausgetauscht werden, damit der Code wieder funktioniert. Es geht in diesem Kapitel aber vor allem darum, grundlegende Konzepte beim Scrapen mit Selenium anhand eines Beispiels zu verstehen. In der Sitzung werden wir den Code für die aktuelle Version der Website umschreiben.
9.3.1. Recap: Elemente suchen und Text extrahieren#
Zu Beginn laden wir wieder alle notwendigen Bibliotheken und Module, starten eine Sitzung und veranlassen den Browser, eine HTTP Get-Anfrage zu stellen:
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("https://www.airbnb.com/")
# Recap: Daten extrahieren
unterkuenfte = driver.find_elements(By.CLASS_NAME, "t1ms2xzu")
unterkuenfte_orte = [unterkunft.text for unterkunft in unterkuenfte]
unterkuenfte_orte
driver.quit()
Dieser Code hat eine große Schwäche: Wenn die Inhalte noch nicht ganz fertig geladen und gerendert sind, wenn wir den Text mit unterkunft.text extrahieren wollen, bekommen wir eine Fehlermeldung, die uns darauf aufmerksam macht, dass das Element nicht gefunden werden konnte. Die aktuelle Sitzung wird dabei nicht geschlossen, und der Prozess läuft im Hintergrund weiter. Das könnt ihr im ActivityMonitor (Mac) bzw. TaskManager (Windows) einsehen, indem ihr nach dem Prozess “chromedriver” sucht.
Um das Problem zu lösen, müssen zwei Sachen geschehen: Zum Einen muss der Code so geschrieben werden, dass die Sitzung sicher geschlossen wird, auch dann, wenn eine Fehlermeldung geworfen wird. Dazu kann das bereits aus dem Abschnitt “8.2.3.3. Daten schreiben” bekannte Konstrukt with ...as verwendet werden:
from selenium import webdriver
from selenium.webdriver.common.by import By
# ChromeDriver als Context Manager
with webdriver.Chrome() as driver:
driver.get("https://www.airbnb.com/")
unterkuenfte = driver.find_elements(By.CLASS_NAME, "t1ms2xzu")
unterkuenfte_orte = [unterkunft.text for unterkunft in unterkuenfte]
unterkuenfte_orte
Zum Anderen muss eine Wartestrategie eingebaut werden, mit der wir warten, bis die entsprechenden Elemente geladen haben. Wir könnten das Problem naiv mit der bisher bekannten Funktion time.sleep() lösen:
# naive Lösung mit time.sleep()
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
with webdriver.Chrome() as driver:
driver.get("https://www.airbnb.com/")
time.sleep(5)
# Recap: Daten extrahieren
unterkuenfte = driver.find_elements(By.CLASS_NAME, "t1ms2xzu")
unterkuenfte_orte = [unterkunft.text for unterkunft in unterkuenfte]
unterkuenfte_orte
Allerdings hängt die Ladezeit beim Seitenaufruf mit Selenium noch viel mehr von der Netzwerkgeshwindigkeit und anderen äußeren Faktoren ab als beim Seitenaufruf mit requests. Dadurch kann es schnell passieren, dass die angegebene Wartezeit viel zu lang oder viel zu kurz ist. Zum Glück bietet Selenium selbst Methoden zur feingranularen Kontrolle über das Warteverhalten des automatisierten Webbrowsers, mit denen das Problem deutlich eleganter und effizienter gelöst werden kann.
9.3.2. Selenium Waits#
Beim Web Scrapen mithilfe von Selenium sollten immer Wartezeiten eingebaut werden, die sicherstellen, dass der automatisierte Browser genug Zeit zum Laden der gesuchten Inhalte hat. Das Selenium webdriver-Modul bietet eigene Methoden, die ermöglichen, nicht nur eine feste Anzahl an Sekunden wie mit der bereits bekannten Funktion time.sleep() zu warten, sondern beim Warten verschiedene Strategien anzuwenden. Bei diesen Wartestrategien wird unterschieden zwischen “Implicit Waits”, “Explicit Waits” und sogenannten “Fluent Waits”. Fluent Waits klammern wir hier aus; dabei handelt es sich nur um eine erweiterte Variante der “Explicit Waits” mit mehr Konfigurationsmöglichkeiten (zum Nachlesen empfehle ich diesen Blogbeitrag sowie den entsprechenden Abschnitt in den Selenium-Dokumentationsseiten).
Zunächst betrachten wir die Methode driver.implicitly_wait(x), die ermöglicht, für alle Suchvorgänge innerhalb einer Session einzustellen, dass x Sekunden lang auf jedes gesuchte Element gewartet wird, bevor eine “ElementNotFound”-Ausnahme geworfen wird. Am Beispiel der Suche nach den Airbnb-Ortsangaben sieht die Verwendung von implicitly_wait() so aus:
# Implicit Wait
from selenium import webdriver
from selenium.webdriver.common.by import By
with webdriver.Chrome() as driver:
driver.implicitly_wait(10)
driver.get("https://www.airbnb.com/")
unterkuenfte = driver.find_elements(By.CLASS_NAME, "t1ms2xzu")
unterkuenfte_orte = [unterkunft.text for unterkunft in unterkuenfte]
unterkuenfte_orte
Die Verwendung von driver.implicitly_wait(x) ist effizienter als die Variante mit time.sleep(x), denn während die Ausführung des Skripts mit time.sleep(x) immer um genau x Sekunden verzögert wird, wird mit implicitly_wait(x) maximal x Sekunden gewartet. In vielen Fällen ist die Wartezeit aber kürzer, weil das gesuchte Element schon früher, vor Ablauf der x Sekunden gefunden werden kann, oder länger, weil der Verbindungsaufbau sich verzögert. Außerdem wird durch Verwenden der Selenium-Wartestrategien verhindert, dass das Programm unkontrolliert abbricht, wenn ein Element nicht gefunden wird.
Allerdings muss beachtet werden, dass mit .implicitly_wait() NICHT darauf gewartet wird, ob der Inhalt des Elements bereits so weit geladen ist, dass man damit interagieren kann, oder dass es auf der Seite sichtbar ist, sondern es wird nur darauf gewartet, ob das Element selbst im HTML-Baum gefunden werden kann. Wenn das Element bereits vor dem Laden der Inhalte mit JavaScript im Skelett der Website vorhanden ist, aber noch keine Inhalte enthält, wie in diesem Fall auf der Airbnb-Seite (erinnert euch an den Abschnitt “Statisch vs. Dynamisch?”), dann kann .implicitly_wait() NICHT verwendet werden.
Neben der globalen Wartezeit mit .implicitly_wait() gibt es in Selenium deswegen auch die Möglichkeit, explizit auf ein bestimmtes Element zu warten und dabei festzulegen, ob gewartet werden soll, ob das Element sichtbar, anklickbar, auffindbar oder auf andere Weise interagierbar sein soll. Für solche expliziten Wartestrategien (oder “Explicit Waits”) gibt es zwei Möglichkeiten:
# Explicit Wait: Option 1
# Beispiel entnommen aus https://www.selenium.dev/selenium/docs/api/py/webdriver_support/selenium.webdriver.support.wait.html#example
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.common.by import By
with webdriver.Chrome() as driver:
driver.get("https://www.airbnb.com/")
wait = WebDriverWait(driver, timeout=10)
unterkunft = wait.until(lambda x: x.find_element(By.CLASS_NAME, "t1ms2xzu"))
if unterkunft.is_displayed():
print(unterkunft.text)
# Explicit Wait: Option 2
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
with webdriver.Chrome() as driver:
driver.get("https://www.airbnb.com/")
wait = WebDriverWait(driver, 20)
unterkuenfte = wait.until(
EC.visibility_of_all_elements_located((By.CLASS_NAME, "t1ms2xzu"))
)
unterkuenfte_orte = [unterkunft.text for unterkunft in unterkuenfte]
unterkuenfte_orte
Bei beiden Versionen wird so lange gewartet, bis das gesuchte Element bzw. die gesuchten Elemente mit der angegeben Klasse sichtbar sind (also einfach gesagt, bis sie gerendert wurden, mehr Details dazu hier). Die erste Version lässt sich allerdings nicht so leicht für die Suche nach mehreren Elementen umschreiben. Für unser Airbnb-Beispiel verwenden wir deswegen die zweite Strategie.
Mit dieser Strategie des expliziten Wartens kann auch auf eine Reihe anderer Ereignisse gewartet werden. Eine ausführliche Erläuterung dazu findet ihr hier, und eine Liste aller Ereignisse, auf die gewartet werden kann sowie der entsprechenden Methoden findet ihr hier.
Explizite und implizite Wartestrategien sollten allerdings nicht vermischt werden! Laut Selenium-Dokumentationsseiten kann dies zu unerwartetem Verhalten führen:
Warning: Do not mix implicit and explicit waits. Doing so can cause unpredictable wait times. For example, setting an implicit wait of 10 seconds and an explicit wait of 15 seconds could cause a timeout to occur after 20 seconds.
Quelle: Selenium 2024
Mehr zu impliziten und expliziten Wartestrategien in Selenium könnt ihr hier nachlesen.
9.3.3. Scrollvorgang und Mausklick simulieren#
Aber zurück zu unserem AirBnB Beispiele. Bisher haben wir nur Unterkünfte von der Startseite gescraped. Jetzt wollen wir dasselbe für die “Tiny homes”-Seite wiederholen. Beim manuellen Vorgehen würden wir dabei zuerst auf das Tiny homes-Icon klicken. Um diesen Vorgang in Selenium zu simulieren, muss erst das entsprechende HTML-Element eindeutig identifiziert werden, und danach kann mithilfe der Selenium-Methode .click() der Mausklick auf das Element simuliert werden. Um das Element zu suchen, verwenden wir als erstes wieder die Browser-Entwicklertools: Mit Rechtsklick auf das Icon und Auswahl von “Inspect” wird der Quelltext der Seite automatisch an der richtigen Stelle in den Entwicklertools geöffnet. Häufig wird nicht exakt das gesuchte Element markiert, sondern ein Kind- oder Elternelement. Das richtige Element ist das div-Element, nicht dessen Kindelement span oder img:
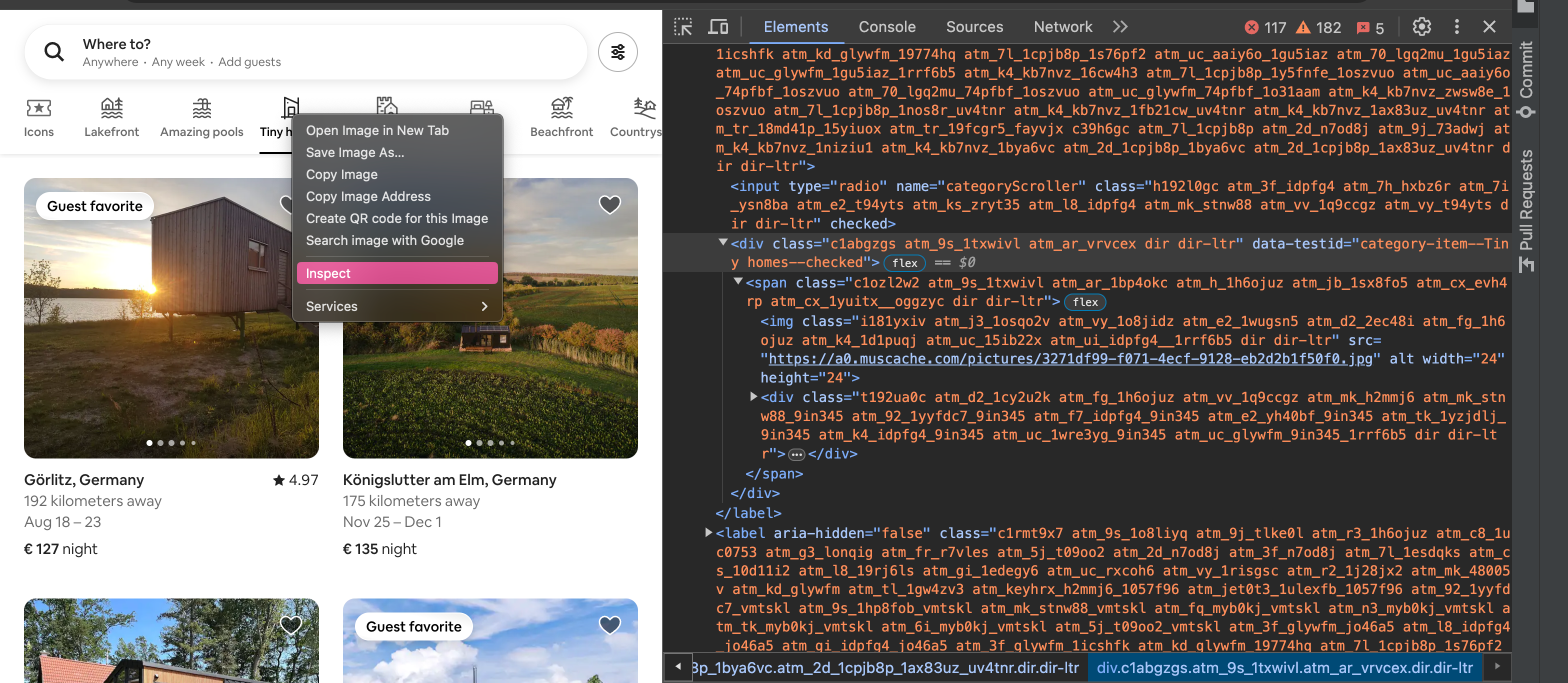
Fig. 9.9 Tiny homes-Icon in den Entwicklertools#
Welches Attribut identifiziert das Icon-Element eindeutig? Das Icon-Element hat ein “class”-Attribut, das allerdings eine lange Zeichenkette als Wert hat. Das kann vorkommen, wenn mehrere CSS-Klassen zur Identifizierung eines HTML-Elements verwendet werden. Verschiedene Klassen werden dabei durch ein Leerzeichen getrennt. Das Leerzeichen verursacht aber bei der Suche mit By.CLASS_NAME ein Problem und führt dazu, dass der Code eine Fehlermeldung produziert. Bei einer so langen Zeichenkette wäre das manuelle Ersetzen der Leerzeichen durch Punkte hier jedoch keine gute Lösung. Stattdessen könnten wir überprüfen, ob das gesuchte Element schon durch die erste CSS-Klasse oder nur einige wenige Klassen eindeutig definiert wird. Das können wir überprüfen, in dem wir in den Entwicklertools mit der Tastenkombination STRG + F nach der ersten CSS-Klasse suchen. Es zeigt sich: Das Tiny homes Icon ist nicht das einzige Element, das diese CSS-Klasse hat; sondern es gibt sehr viele Elemente mit dieser Klasse:
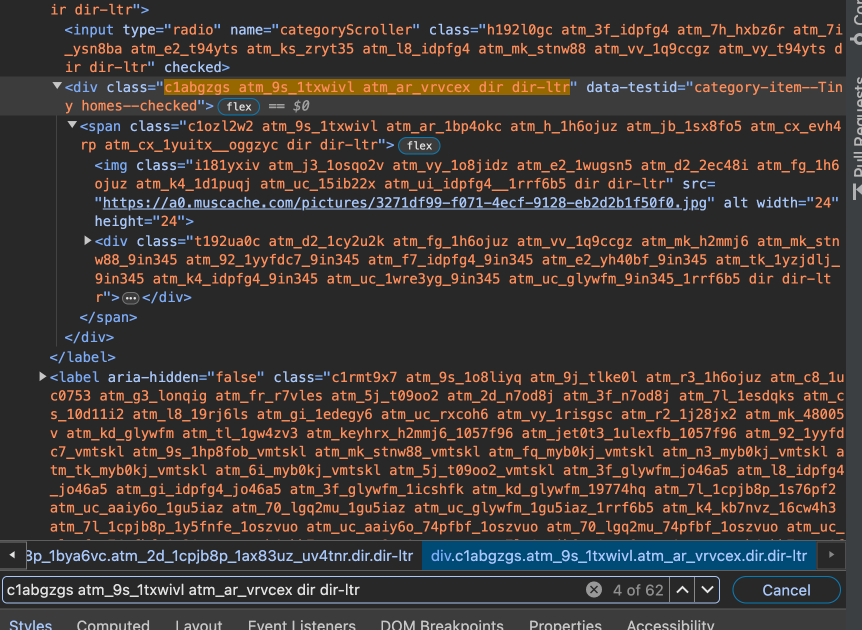
Fig. 9.10 Suche nach class-Attributen mit dem Wert “c1abgzgs atm_9s_1txwivl atm_ar_vrvcex dir dir-ltr”.#
Wir können also das Icon-Element nicht eindeutig über die gewählte CSS-Klasse addressieren. Wir könnten jetzt natürlich verschiedene Kombinationen von CSS-Klassen ausprobieren, aber das Icon-Element hat noch ein weiteres Attribut, über das das Button-Element etwas einfacher addressiert werden kann: Das Attribut data-testid mit dem Wert “category-item–Tiny homes–checked”. Wenn der Tab nicht geöffnet ist, hat das Attribut allerdings den Wert “category-item–Tiny homes–unchecked”. Das kann überprüft werden, indem mit STRG + F nach allen Attributen mit dem Wert “category-item” gesucht wird. Wir verwenden anstelle des class-Attributs also das data-testid-Attribut für die Suche nach dem Tiny homes Icon-Element und definieren dazu einen sogenannten XPath-Ausdruck. XPath ist eine Pfadbeschreibungssprache, mit der HTML-Elemente anhand ihrer Hierarchie, Attributen, Textinhalten und weiteren Eigenschaften lokalisiert werden können. So können wir zum Beispiel das Icon-Element mit dem XPath-Ausdruck //div[@data-testid='category-item--Tiny homes--unchecked'] auswählen. Dieser Ausdruck sucht nach einem Element mit den Namen div (div), irgendwo im HTML-Baum (//), das ein Attribut data-testid mit dem Wert “category-item–Tiny homes–unchecked” hat ([@data-testid='category-item--Tiny homes--unchecked']).
Nachdem das Element gefunden wurde, kann der Mausklick mit der Selenium-Methode .click() simuliert werden:
# Driver-Instanz starten und Wartezeit einstellen
with webdriver.Chrome() as driver:
wait = WebDriverWait(driver, 10)
tinyhomes_button = wait.until(EC.element_to_be_clickable((By.XPATH, "//div[@data-testid='category-item--Tiny homes--unchecked']")))
# Auf den Tiny House Icon klicken: Nach dem Klick "category-item--Tiny Houses--checked", vor dem Klick "category-item--Tiny homes--unchecked"
tinyhomes_button.click()
Nachdem sich die Tiny homes-Seite geöffnet hat, muss zum Seitenende gescrollt werden, wo sich der “Show more” Button befindet. Wir sollten zunächst überprüfen, ob der Button bereits beim Aufruf der Seite geladen wird. Dazu können wir manuell zum Seitenende scrollen, mit Rechtsklick und Inspect den “Show more”-Button in den Entwicklertools anzeigen lassen, und die CSS-Klassen in die Zwischenablage kopieren, also den gesamten String “l1ovpqvx…dir-ltr”.
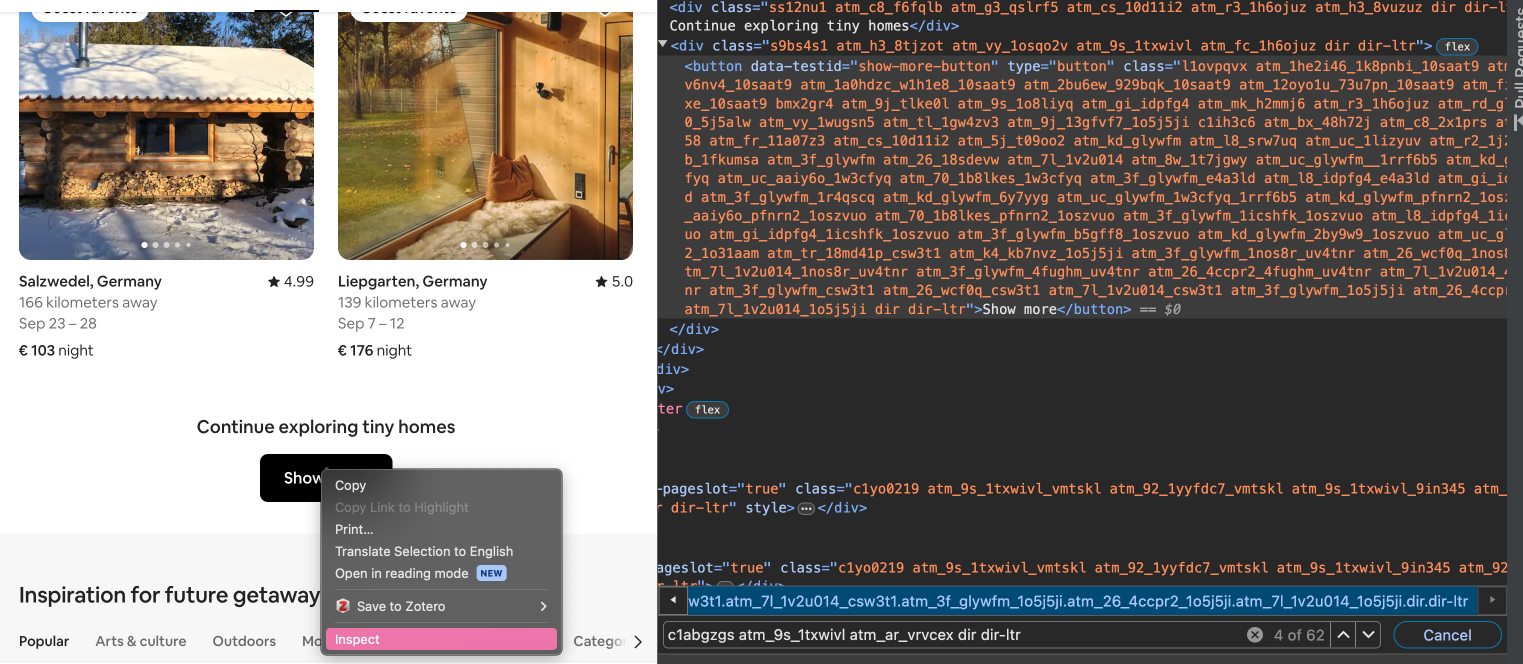
Fig. 9.11 Button-Element in den Entwicklertools.#
Anschließend laden wir die Seite neu und suchen ohne Herunterzuscrollen in den Entwicklertools mit STRG-F nach dem String. Die Suche sollte keine Ergebnisse liefern. Wenn wir jedoch zum Seitenende scrollen und erneut nach dem String suchen, wird das Element nun gefunden und die Suche liefert ein Ergebnis. Das bedeutet: Die Seiteninhalte werden auf der Tiny homes-Seite erst dann geladen, wenn sie sich im aktuellen Anzeigebereich befinden. Diesen Umstand können wir auch überprüfen, indem wir mit Selenium mit .find_element() nach dem Button mit suchen: Die Suche produziert die Fehlermeldung “NoSuchElementException”. Um die restlichen Unterkünfte auf der Startseite sowie den “Show more” Button zu laden, müssen wir also zunächt bis zum Seitenende scrollen.
In Selenium gibt es verschiedene Möglichkeiten, einen Scrollvorgang zu simulieren. Wenn bereits alle Elemente geladen wurden und nur ein Element in den aktuellen Anzeigebereich gescrollt werden soll, kann die Methode .scroll_to_element() verwendet werden (siehe Selenium-Dokumentationsseite und das Code-Snippet zu Scrollstrategie 3 weiter unten). Wie wir gesehen haben, wird der “Show more” Button zusammen mit den restlichen Inhalten allerdings erst durch das Scrollen mithilfe von Javascript in das HTML-Gerüst der Webseite eingefügt. Das gesuchte button-Element wird also beim Aufruf der Seite noch nicht gefunden und die Methode .find_element() produziert entsprechend eine Fehlermeldung “NoSuchElementException”.
Wir betrachten zunächst einen Ansatz, bei dem so lange um eine bestimmte Pixelanzahl nach unten gescrollt wird, bis der bereits durchscrollte Bereich zusammen mit dem aktuell angezeigten Bereich größer oder gleich der Gesamthöhe der Webseite in Pixeln ist.
# Scrollstrategie 1: Um eine festgelegte Pixelanzahl scrollen
scroll_step = 300 # Schrittgröße für jeden Scroll-Vorgang (in Pixeln)
# Erste Seite bis zum Ende scrollen
with webdriver.Chrome() as driver:
driver.get("https://www.airbnb.com/")
time.sleep(5) # nur damit wir sehen, können, was passiert
# Seite bis zum Ende scrollen
while True:
driver.execute_script(f"window.scrollBy(0, {scroll_step});")
time.sleep(2) # nur damit wir sehen was passiert
at_bottom = driver.execute_script(
"return Math.abs(document.documentElement.scrollHeight "
"- document.documentElement.clientHeight "
"- document.documentElement.scrollTop) <= 1;"
)
if at_bottom:
break
Wie funktioniert das Scrollen? .execute_sript() ist eine Selenium-Methode, die zum Ausführen von JavaScript Code Snippets verwendet wird. Die Aktionen, die im Browser ausgeführt werden sollen, werden in JavaScript geschrieben und der .execute_script()-Methode als Argument übergeben. Der JavaScript-Code ist den JavaScript-Dokumentationsseiten, und zwar dem Abschnitt “Determine if an element has been totally scrolled” entnommen.
Zum Verständnis des Codes ist an dieser Stelle ein bisschen JavaScript-Kenntnis (bzw. Recherche in den JavaScript-Dokumentationsseiten) erforderlich:
documentElementrepräsentiert in JavaScript das Wurzelelement eines HTML-Dokuements, also z.B. das html-Element (siehe JavaScript-Dokumentationsseite). Da darin der gesamte Seiteninhalt enthalten ist, können wir das Wurzelelement der Seite gut nutzen, um zu bestimmen, ob der Seiteninhalt durchscrollt wurde..scrollBy()ist eine JavaScript-Methode, die laut Dokumentationsseite das im Browserfenster geöffnete HTML-Dokument um die angegebene Pixelanzahl scrollt. Das erste Argument gibt dabei die Pixel an, um die in horizontaler Richtung gescrollt werden soll. Das zweite Argument gibt die Pixel für das vertikale Scrollen an..scrollHeightist eine Eigenschaft, die laut Dokumentationsseite die Höhe des Inhalts eines HTML-Elements (hier also des Wurzelelements der Seite) in Pixeln angibt, und zwar sowohl für den sichtbaren als auch für den unsichtbaren Bereich, also die Gesamthöhe der scrollbaren Inhalte. Mit “unsichtbarer Bereich” ist der Bereich gemeint, der aufgrund des Scrollens außerhalb des aktuell sichtbaren Bereichs liegt..scrollTopist eine Eigenschaft, die laut Dokumentationsseite die Anzahl an Pixeln angibt, um die ein der Inhalt eines HTML-Elements bereits in vertikaler Richtung durchscrollt wurde, also die aktuelle Scroll-Position in vertikaler Richtung..clientHeightist eine Eigenschaft, die laut Dokumentationsseite die innere Höhe eines HTML-Elements in Pixeln angibt. Für das Wurzelelement ist das der Viewport, also der Bereich, in dem tatsächlich die Webseite angezeigt wird, ohne die Scrollleiste, URL-Zeile, die Tabs, usw. Mehr dazu hier.returnist das JavaScript-Pendant zur return-Anweisung in Python, die in Funktionsaufrufen verwendet wird, um einen Wert zurückzugeben. Wie genau diese Werte extrahiert werden, müssen wir nicht unbedingt wissen, um den Code zu verwenden. Aber wenn sich jemand nähergehend damit beschäftigen möchte, empfehle ich diese Seite.
Unter den folgenden Links findet ihr weitere Hintergrundinformationen und Anwendungsbeispiele zur .execute_sript() Methode:
https://www.selenium.dev/documentation/webdriver/interactions/windows/#execute-script
https://docs.pylenium.io/driver-commands/browser/execute_script
Den Zusammenhang zwischen den verschiedenen Objekteigenschaften und ihre Bedeutung für Abbruchbedingung der while-Schleife lässt sich vielleicht ungefähr so veranschaulichen:
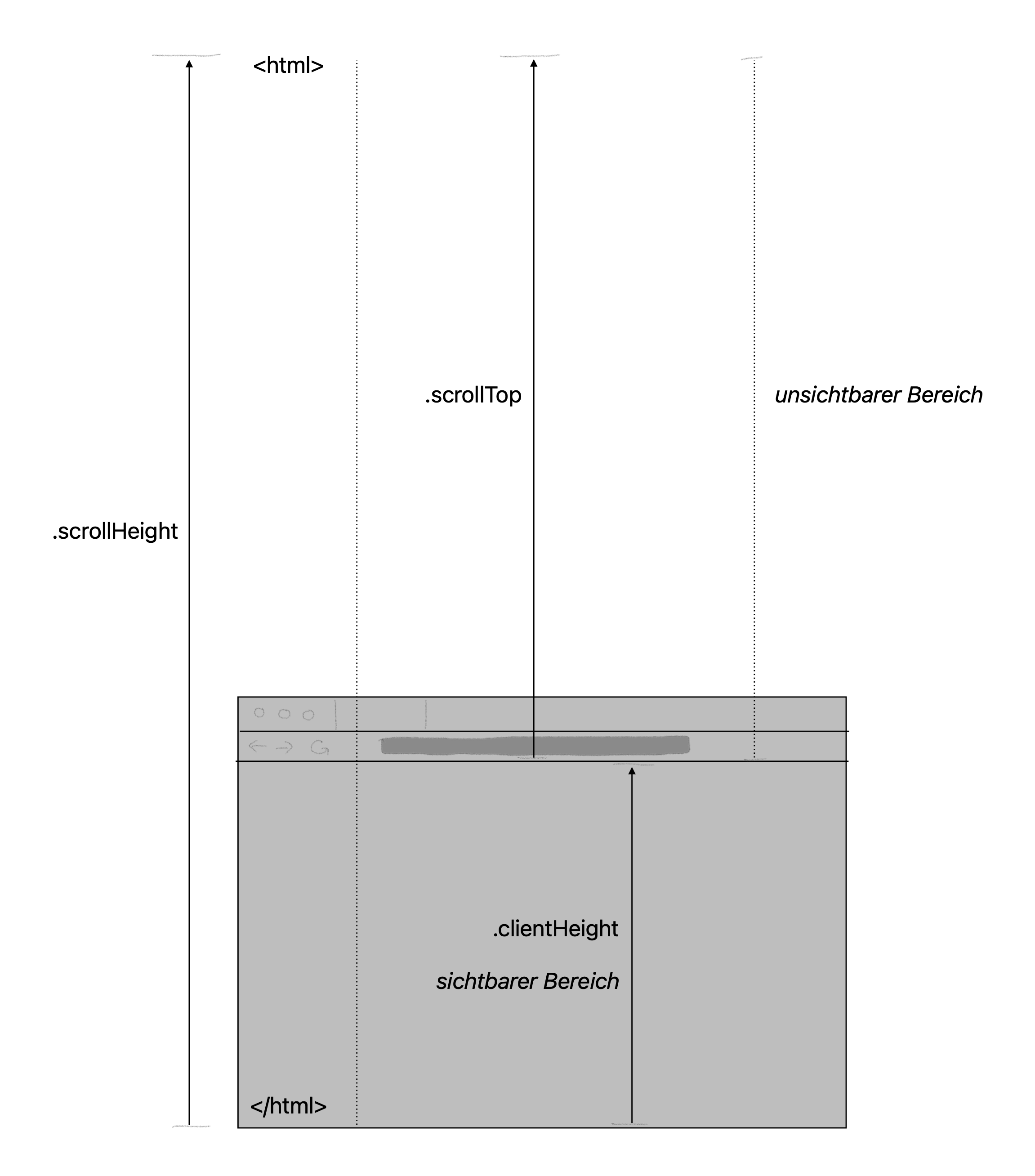
Fig. 9.12 Veranschaulichung der JavaScript-Objekteigenschaften zur Formulierung der Abbruchbedingung.#
Wenn das Seitenende erreicht ist und die while-Schleife terminiert, kann der Mausklick auf den “Show more”-Button simuliert werden. Anschließend sollte wieder ein paar Sekunden gewartet werden, damit die neuen Inhalte laden können.
# Button "Show More" klicken: Diesmal mit JavaScript
wait = WebDriverWait(driver, 10)
more_button = wait.until(EC.element_to_be_clickable((By.XPATH, "//button[contains(text(), 'Show more')]")))
driver.execute_script("arguments[0].click();", more_button)
Zum Klick auf den Button kann entweder wieder die Selenium-Methode .click() verwendet werden wie beim Klick auf den Tiny homes-Icon zuvor. Oder es wird wieder ein JavaScript Code Snippet ausgeführt, das dafür zuständig ist, den Mausklick im Browser auszulösen. Dazu wird die Selenium-Methode .execute_script() im Zusammenhang mit der Javascript-Methode .click() verwendet. Die JavaScript-Methode heißt ebenfalls .click() und ist genau wie die Selenium-Methode .click() für HTML-Elemente definiert, aber eben für JavaScript und nicht Python. Im Codebeispiel unten steht arguments[0] für das HTML-Element, das angeklickt werden soll. Das Element muss deswegen wieder zuerst gesucht werden und einer Variable zugewiesen werden. Diese Variable (hier more_button) wird der .execute_script()-Methode als Argument übergeben. arguments[0] verweist dann auf das Argument.
Anschließend muss wieder bis zum Seitenende gescrollt werden, damit alle Unterkünfte laden. “Laden” bedeutet hier zur Erinnerung, dass die neuen Inhalte in das HTML-Gerüst eingefügt werden und dadurch addressierbar werden. Der manuelle Scrollvorgang hat gezeigt, dass die Inhalte dynamisch geladen werden, sobald sie durch Scrollen in den sichtbaren Bereich gelangen. Aber anders als bei einem Infinite Scrolling endet die Seite nach einigen Scrollvorgängen. Wir könnten also beim Scrollen genauso vorgehen, wie beim Scrollen zum “Show more”-Button. Allerdings war dieser Scrollvorgang recht langsam, weil in jedem Schleifendurchlauf nur um 300 Pixel gescrollt wurde. Wir könnten also, um den Vorgang etwas zu beschleunigen, zum Beispiel die Pixelanzahl vergrößern. Hierbei sollte allerdings Folgendes bedacht werden: Je nachdem, wie groß das Browserfenster auf unterschiedlichen Geräten ist, haben auch die Kacheln mit den Unterkünften eine unterschiedliche Größe und es gibt unterschiedlich viele Kacheln in einer Zeile. Es werden also je nach Größe des Browserfensters verschieden viele Kacheln geladen, wenn um 300, 500 oder 800 Pixel gescrollt wird. Wenn zu schnell gescrollt wird, dann können Inhalte nicht rechtzeitig geladen werden, und wenn das passiert, werden sie folglich von unserem Webscraper nicht gefunden.
Zum Scrollen verwenden wir deswegen diesmal einen etwas zeiteffizienteren alternativen Ansatz, bei dem in jedem Schleifendurchlauf nicht um eine feste Pixelanzahl gescrollt wird, sondern um die innere Höhe des Browserfensters (“Viewport” bzw. Eigenschaft .clientHeight). Das JavaScript-Code-Snippet, das wir bei der ersten Strategie zur Formulierung der Abbruchbedingung verwendet haben, übersetzen wir außerdem bei dieser Scrollstrategie in Python-Variablen. Das ist etwas sauberer, weil wir die Formulierung der Abbruchbedingung direkt in Python formulieren und nicht in einen String auslagern.
# Scrollstrategie 2: Um die Fenstergröße scrollen
with webdriver.Chrome() as driver:
driver.get("https://www.airbnb.com/")
time.sleep(5)
viewport_height = driver.execute_script("return document.documentElement.clientHeight;")
# Seite bis zum Ende scrollen
while True:
driver.execute_script(f"window.scrollBy(0, {viewport_height});")
time.sleep(2)
scroll_height = driver.execute_script("return document.documentElement.scrollHeight;")
scroll_position = driver.execute_script("return document.documentElement.scrollTop;")
if scroll_height - viewport_height - scroll_position <= 1:
break
Wenn die Schleife terminiert, ist der gesamte Seiteninhalt durchscrollt und gerendert.
Bevor wir die Inhalte von der durchscrollten Seite extrahieren, betrachten wir noch eine letzte, alternative Scrollstrategie. Bei dieser Scrollstrategie wird die Selenium “Actions API” verwendet, um eine Abfolge von Aktionen zu definieren, eine sogenannte ActionChain, die nacheinander ausgeführt werden. Das ActionChain-Objekt hat verschiedene Methoden. Mit der Methode .scroll_from_origin() kann entweder um eine bestimmte Pixelanzahl gescrollt werden, oder es kann mit .scroll_to_element() direkt zu einem konkreten Element gescrollt werden, zum Beispiel dem Footer der Seite. Mit .pause(1) kann die ActionChain dabei ganz einfach mit einem Methodenaufruf pausiert werden. Das klingt auf den ersten Blick deutlich praktischer als unsere Strategie mit dem JavaScript Code. Aber Achtung: Diese Scrollstrategie funktioniert nicht mit allen Webdrivern und Browsern! Zum Nachlesen, welche Browser aktuell unterstützt werden, schaut euch die Seite “Scroll wheel actions” in den Selenium-Dokumentationsseiten an. Um direkt zu einem Element zu scrollen, muss dieses beim Aufruf der Seite natürlich außerdem bereits im HTML-Gerüst vorhanden sein.
# Scrollstrategie 3: Zu einem bestimmten Element scrollen
import time
from selenium.webdriver import ActionChains
from selenium.webdriver.common.actions.wheel_input import ScrollOrigin
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
with webdriver.Chrome() as driver:
driver.get("https://www.airbnb.com/")
wait = WebDriverWait(driver, 10)
footer = wait.until(
EC.presence_of_element_located((By.TAG_NAME, "footer"))
)
ActionChains(driver)\
.scroll_to_element(footer)\
.perform()
time.sleep(5) # nur damit wir sehen was passiert
Nach dem Scrollen können wieder die Ortsangaben extrahiert werden. .find_elements() findet nach dem Scrollen jetzt nicht nur die ersten 20 Suchergebnisse, sondern alle Ergebnisse. Hierzu können wir wieder entweder das class-Attribut verwenden und die CSS-Klassen abkürzen, oder wir formulieren einen XPATH-Ausdruck zur Suche nach einem anderen Attribut, beispielsweise das Attribut data-testid:
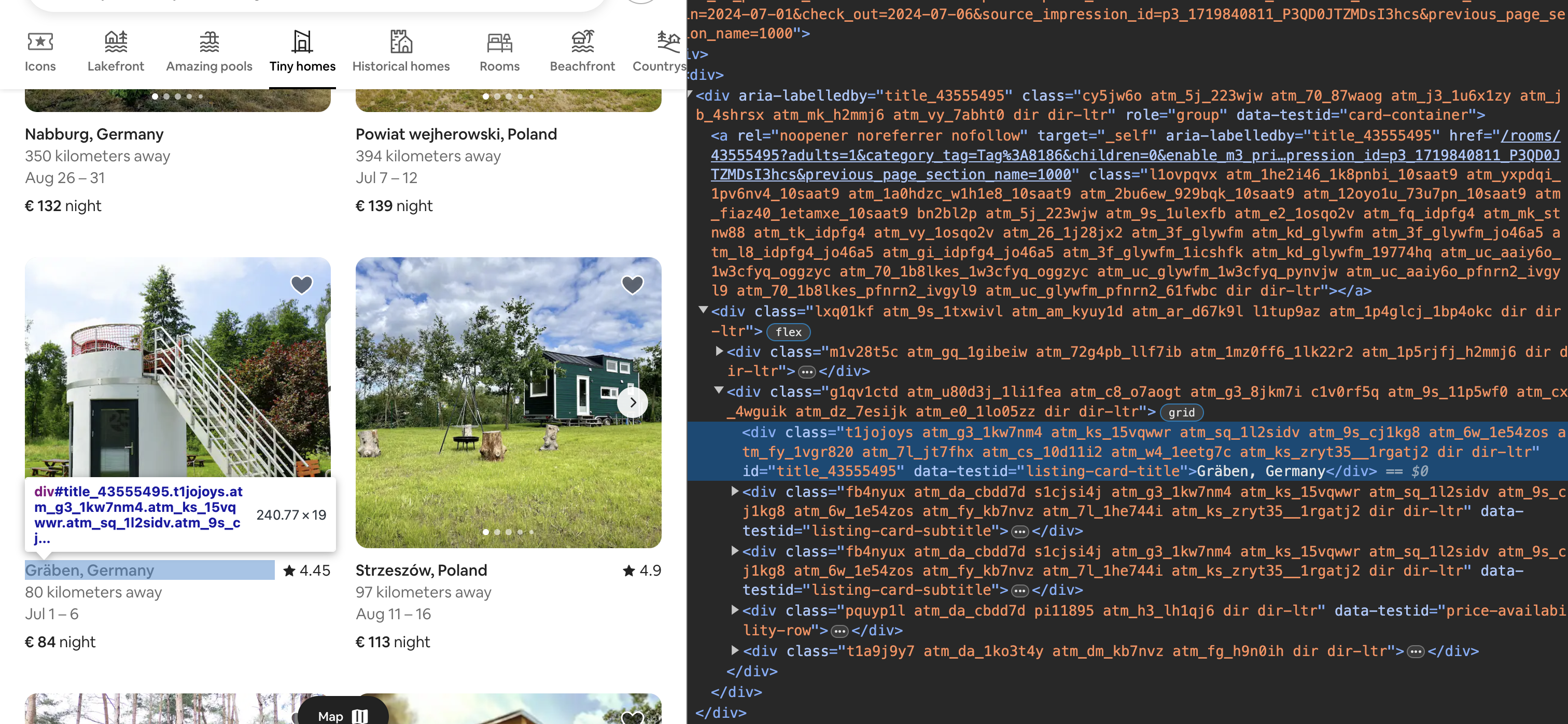
Fig. 9.13 Unterkunft in den Entwicklertools untersuchen.#
# Daten extrahieren
wait = WebDriverWait(driver, 10)
unterkuenfte = wait.until(
EC.visibility_of_all_elements_located((By.XPATH, "//div[@data-testid='listing-card-title']")) # Alternativ By.CLASS_NAME, "t1jojoys"
)
unterkuenfte_orte = [unterkunft.text for unterkunft in unterkuenfte]
unterkuenfte_orte
Falls ihr ChromeDriver nicht wie hier als ContextManager verwendet habt, müsst ihr noch das aktuelle Browserfenster und die Session, also die Sitzung, welche durch den Aufruf des Chrome Webdrivers gestartet wird, schließen:
# optional, falls ihr den WebDriver nicht als ContextManager mit with ... verwendet
driver.quit()
Zum Abschluss möchte ich noch auf diesen vierten Ansatz zum Scrollen mithilfe von Selenium von David Shivaji verweisen.
Verständnisfrage
Überlegt selbst: Welche Vor-/Nachteile hat dieser Ansatz? Welche Parameter werden dabei verwendet?
9.3.4. Suche benutzen und Tastatureingabe simulieren#
Bisher haben wir die Ortsangaben zu Unterkünften extrahiert, die zufällig auf der Startseite angezeigt wurden. Meistens interessieren wir uns aber für ganz bestimmte Daten, zum Beispiel nur Unterkünfte in Berlin zu einem bestimmten Zeitpunkt. Als nächstes sehen wir uns also an, wie mithilfe von Selenium die Suchmaske auf airbnb.com verwendet werden kann und wie eine Tastatureingabe getätigt werden kann.
Zunächst starten wir wieder den Webdriver und senden eine Anfrage für die Seite https://www.airbnb.com/ und schließen das Popup-Fenster. Beachtet allerdings, dass wir ein zusätzliches Modul importieren, das wir später zur Simulation der Tastatureingabe benötigen.
# Vorbereitung
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
with webdriver.Chrome() as driver:
driver.get("https://www.airbnb.com/")
Als nächstes wollen wir nach Unterkünften in Berlin suchen. Dazu führen wir die Suche wieder zuerst in unserem regulären Chrome Browser aus, um herauszufinden, mit welchen Bestandteilen des User Interfaces bei der Suche interagiert werden muss. Als erstes geben wir “Berlin” in das Suchfeld ein. Im regulären Chrome-Browser können wir, wieder mithilfe der Entwicklertools, feststellen, dass das Suchfeld über ein HTML-input-Element dargestellt wird:
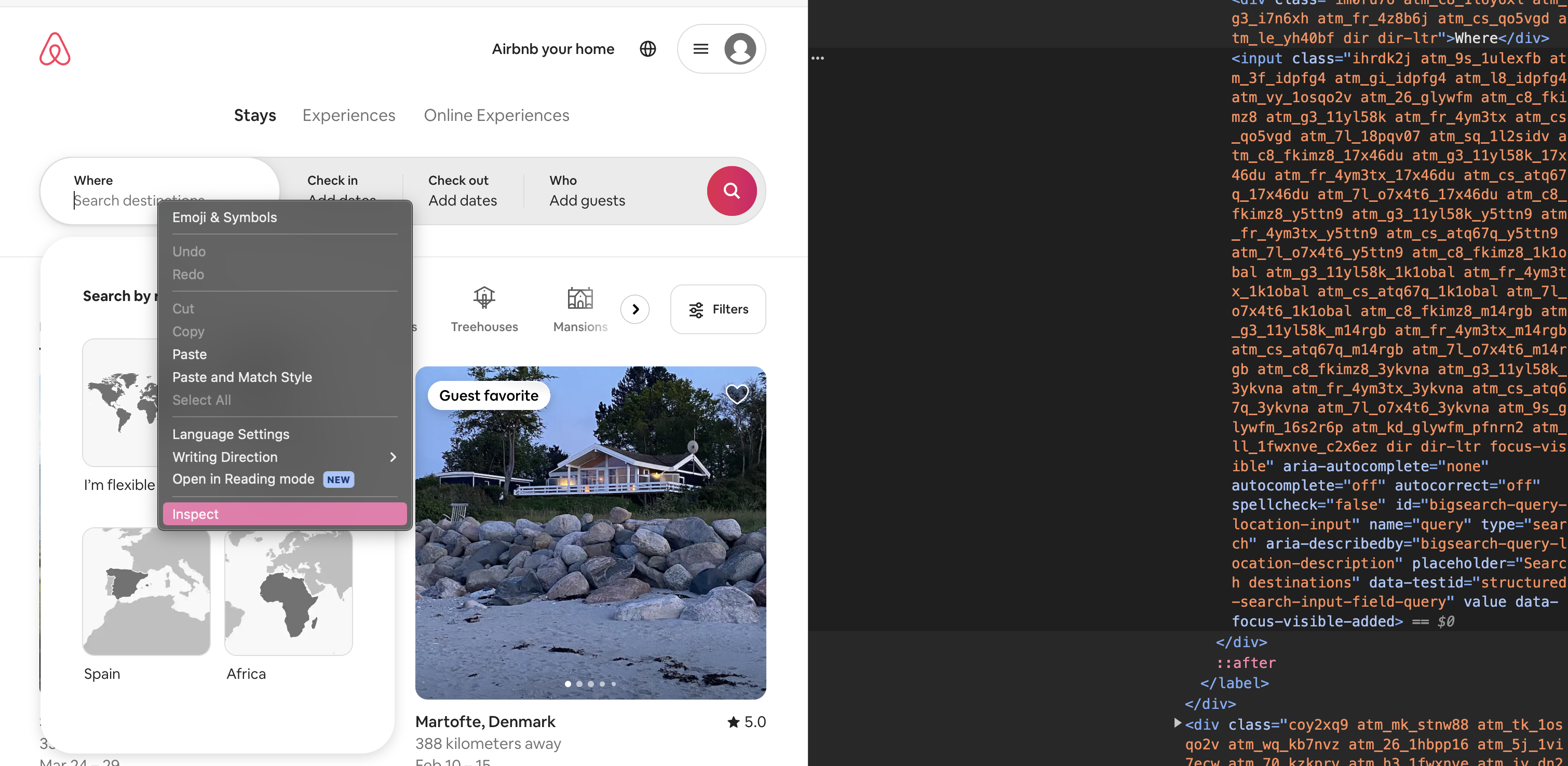
Fig. 9.14 Suchfeld in den Entwicklertools untersuchen.#
Um einen Suchbegriff eingeben zu können, muss das input-Element zunächst gefunden werden. In diesem Fall hat das gesuchte HTML-Element nicht nur ein Attribut class, sondern auch ein Attribut id mit dem Wert, “bigsearch-query-location-input”, welches erlaubt, das Element eindeutig zu identifizieren. Zur Suche können wir nun entweder .find_element(By.ID, “id_des_elements”) oder .find_element(By.XPATH, “xpath_ausdruck”) verwenden. Wenn ihr euch unsicher seid, wie der XPath-Ausdruck formuliert sein muss, könnt ihr aber in diesem Fall die Entwicklertools zur Hilfe nehmen: Der XPath-Ausdruck, der den Pfad zu dem gesuchten Element beschreibt, kann ganz einfach mit Rechtsklick auf ein Element und die Option Copy -> Copy XPath kopiert werden:
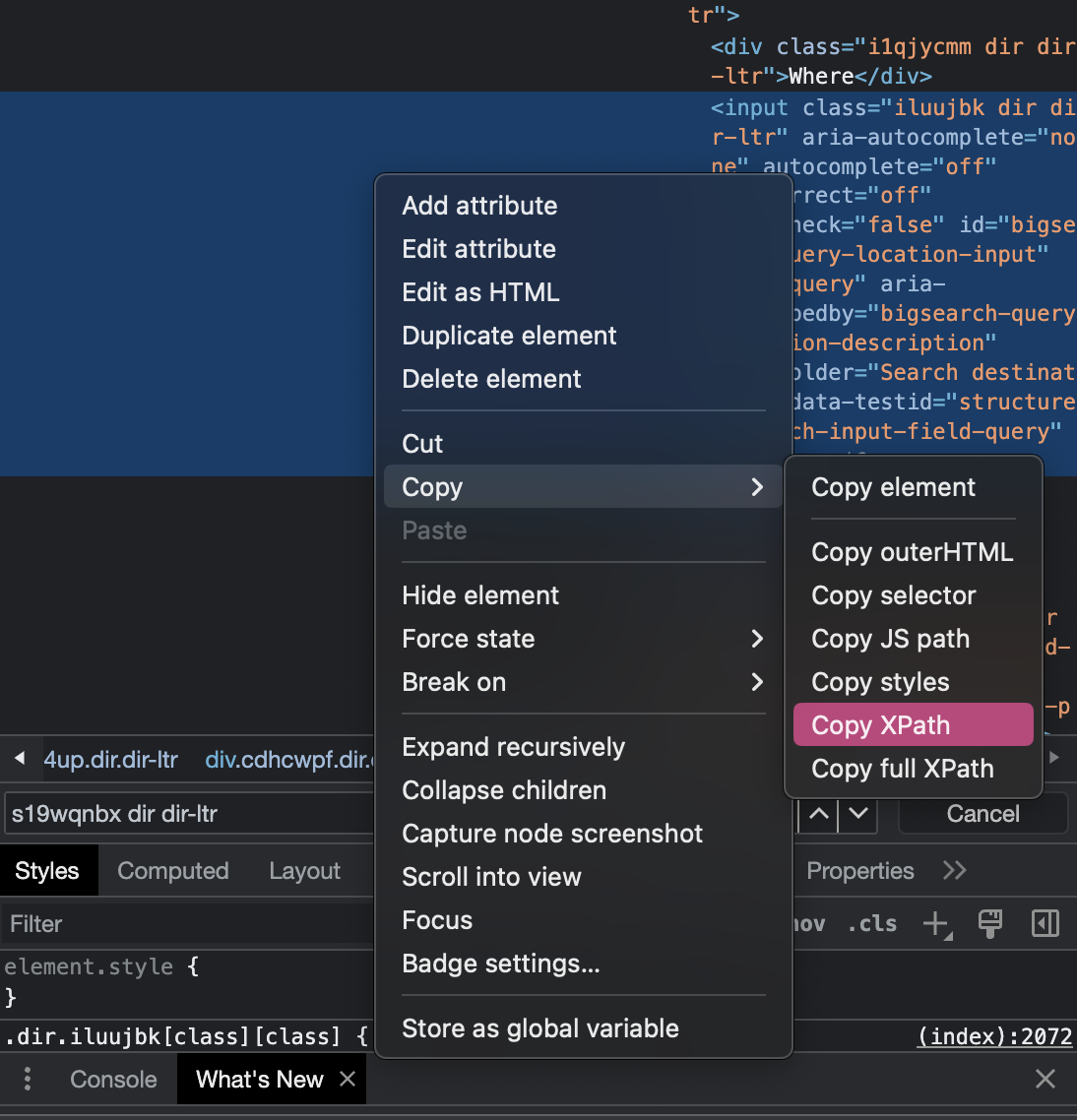
Fig. 9.15 XPath zum gesuchten Element kopieren.#
Der XPath zum gesuchten input-Element ist //*[@id=”bigsearch-query-location-input”]. Das * steht für ein beliebiges HTML-Element, aber wir können auch den Namen des HTML-Elements einsetzen, um bei vielen XPath-Ausdrücken den Überblick zu behalten:
# Input-Element finden, in das die Suchbgegriffe eingegeben werden können
suchfeld = driver.find_element(By.XPATH, "//input[@id='bigsearch-query-location-input']")
Beachtet, dass im Code oben die inneren Anführungszeichen angepasst wurden, um sie von den doppelten äußeren Anführungszeichen zu unterscheiden. Das ist unbedingt notwendig, weil sonst der XPath-Ausdruck nicht richtig interpretiert werden kann.
Wenn das Element gefunden wurde, kann es mithilfe der Methode .send_keys() zur Eingabe eines Suchbegriffs addressiert werden. Die Suche muss anschließend noch durch Betätigung der Enter-Taste bestätigt werden:
# Suchbegriff eingeben
suchfeld.send_keys("Berlin")
Die Suche muss anschließend noch durch Betätigung der Enter-Taste bestätigt werden:
# Tasteneingabe ENTER
suchfeld.send_keys(Keys.ENTER)
Durch Bestätigung der Suche mit Enter wird automatisch ein Fenster zur Auswahl eines Reisetermins geöffnet. Hier wollen wir die Option “flexible” auswählen. Dazu müssen wir zunächst wieder das gesuchte Element identifizieren:
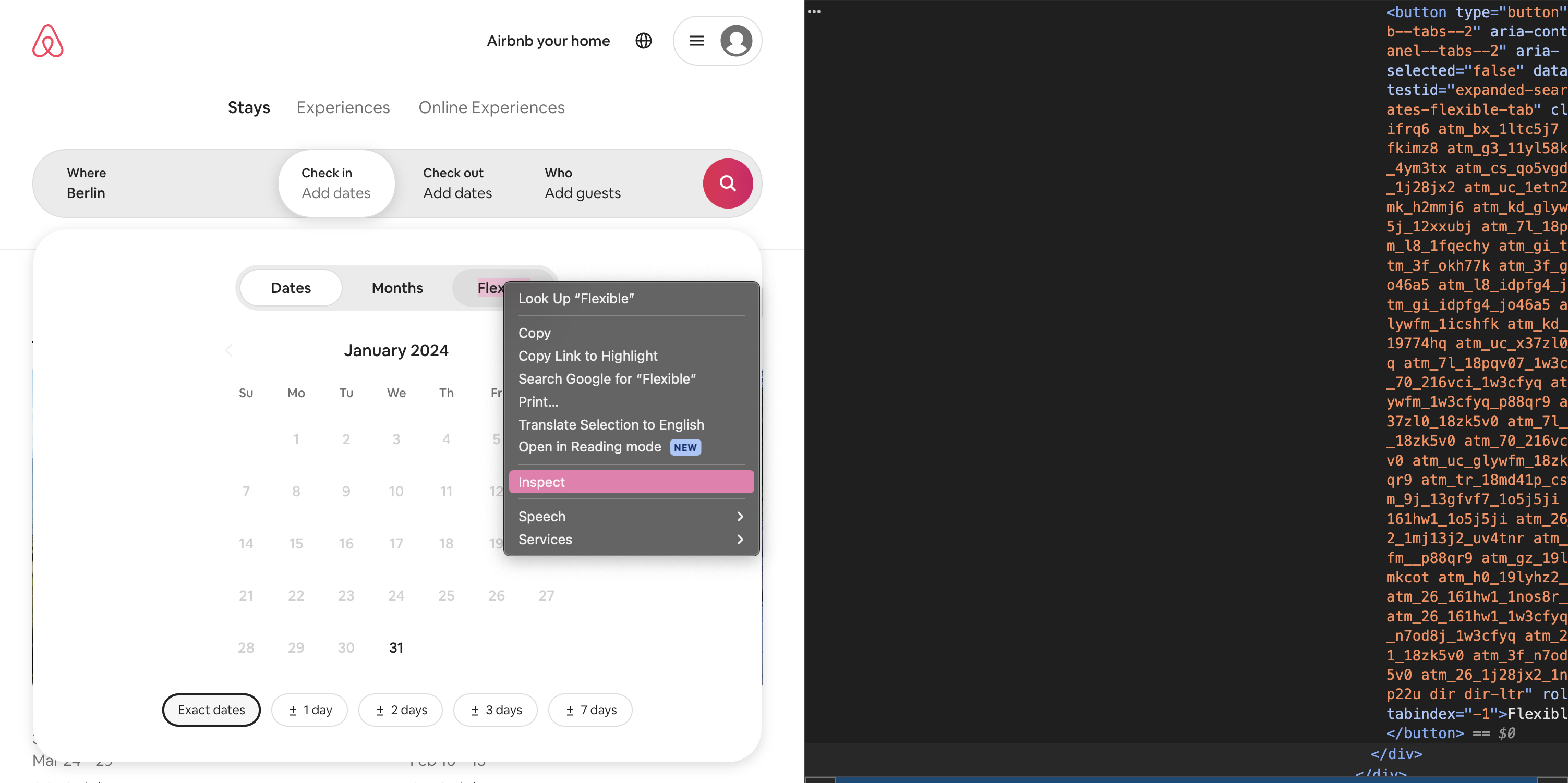
Fig. 9.16 Button “flexible” untersuchen.#
Das gesuchte HTML-Element hat wieder eine ID, über die es eindeutig identifiziert werden kann. Diesmal verwenden wir .find_element(By.ID, “id_des_elements”), damit ihr diese Verwendung der find_element-Methode auch einmal gesehen habt. Die Id könnt ihr einfach aus den Browser-Entwicklertools mit Doppelklick auf das Id-Attribut kopieren.
# Zeit aussuchen: Flexible
driver.find_element(By.ID, "tab--tabs--2").click()
Zuletzt müssen wir unsere Suche noch mit Klick auf den Suchbutton bestätigen. In diesem Fall wird über Rechtsklick auf den Suchbutton und Auswahl der Option “Inspect” allerdings wieder nicht ganz das richtige Element gefunden: Gefunden wird das span-Element mit dem Attribut class="t1dqvypu atm_9s_1ulexfb ..."; gesucht haben wir aber eigentlich den gesamten Suchbutton, also das button-Element mit dem Attribut data-testid=”structured-search-input-search-button”. Bei der Verwendung von “Inspect” ist also immer Mitdenken erforderlich, denn nicht immer wird ganz genau das Element getroffen, das gesucht wird.
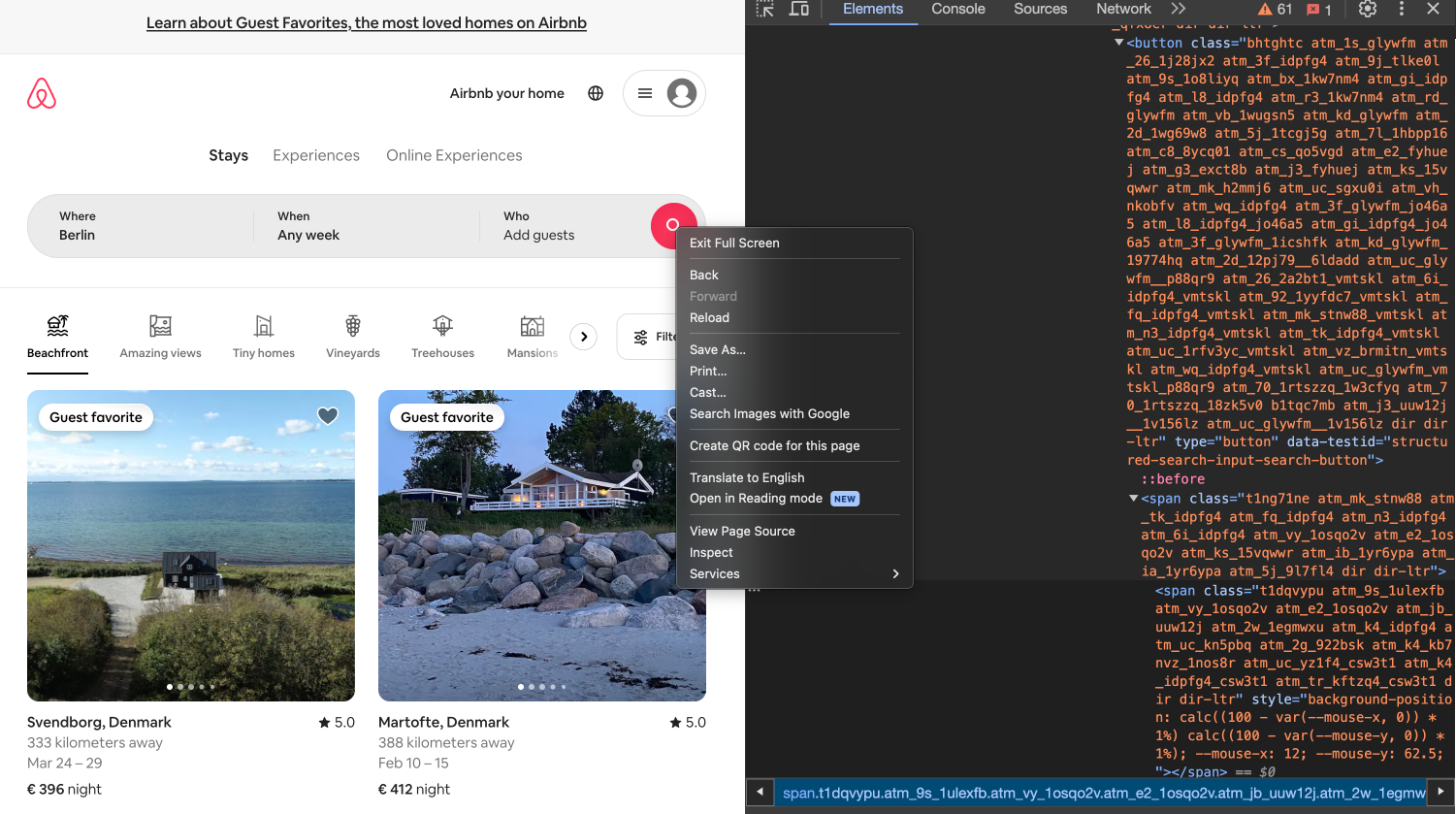
Fig. 9.17 Suchbutton untersuchen.#
Jetzt können wir den Mausklick auf den Suchbutton simulieren:
# Auf den Suchbutton klicken: Suche bestätigen
driver.find_element(By.XPATH, "//button[@data-testid='structured-search-input-search-button']").click()
Zuallerletzt führen wir wieder den Code aus der letzten Stunde aus, um alle Ortsangaben von den ersten 20 vorgeladenen Suchergebnissen zu extrahieren, und beenden die Session:
# Orte extrahieren
unterkuenfte = driver.find_elements(By.XPATH, "//div[@data-testid='listing-card-title']")
unterkuenfte_berlin = [unterkunft.text for unterkunft in unterkuenfte]
# Optional, falls ihr den WebDriver nicht als Context Manager nutzt: Sitzung schließen
driver.quit()
9.3.5. Elemente finden#
In den hier vorgestellten Beispielen wurden verschiedene Methoden verwendet, um Elemente zu finden: manchmal wurde nach der CSS-Klasse gesucht mit driver.find_elements(By.CLASS_NAME, ...), manchmal wurde die ID verwendet mit driver.find_elements(By.ID, ...). Daneben haben wir auch die Pfadbeschreibungssprache XPATH kennengelernt, mit der Elemente im HTML-Baum über ihre Position in der Baumstruktur, ihre Attribute oder einen bestimmten Textinhalt identifiziert werden können. Zur Suche nach Elementen mithilfe von XPATH haben wir die Methode driver.find_elements(By.XPATH, ...) verwendet. Und zuletzt haben wir auch nach Elementen anhand ihres Namens, also des HTML “Tag Namens” gesucht, und zwar mit driver.find_element(By.TAG_NAME, ...). Zu diesen Suchstrategien könnt ihr in den Selenium Dokumentationsseiten im Kapitel “Finding web elements” nachlesen. Wenn die Elemente einmal gefunden sind, können zu den Elementen Eigenschaften abgefragt werden, so wie es auch bei BeautifulSoup-Objekten, Pandas-Dataframes und den Python-Basisdatentypen der Fall war. Welche Eigenschaften Selenium Web-Elemente haben, könnt ihr hier nachlesen.
Einige hilfreiche Ressourcen, mit denen ihr etwas tiefer in XPath einsteigen könnt, sind zum Beispiel:
Tutorial in Videoform mit Beispielen: https://www.youtube.com/watch?v=0QHmDvc9abs
Tutorial in Textform mit Schaubild und Beispielen: https://www.softwaretestinghelp.com/xpath-writing-cheat-sheet-tutorial-examples/
Liste der wichtigsten XPath Ausdrücke: https://www.w3schools.com/xml/xpath_syntax.asp
XPath Cheatsheet: https://devhints.io/xpath
XPath Tester: https://extendsclass.com/xpath-tester.html
9.3.6. Quellen#
JavaScript-BOM-Tutorial. 2023. URL: https://www.webtechnologien.com/advanced-tutorials/javascript-bom/.
David Shivaji. How to Scroll using Selenium in Python. 2021. URL: https://davidshivaji.medium.com/how-to-scroll-using-selenium-in-python-ad1eba1e9bca.
Kuan Wei. Using Python and Selenium to Scrape Infinite Scroll Web Pages. 2020. URL: https://medium.com/analytics-vidhya/using-python-and-selenium-to-scrape-infinite-scroll-web-pages-825d12c24ec7.
MDN Contributors. Element: scrollHeight Property. 2023. URL: https://developer.mozilla.org/en-US/docs/Web/API/Element/scrollHeight.
MDN Contributors. JavaScript: return. 2023. URL: https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Statements/return?retiredLocale=de.
MDN Contributors. Window: innerHeight Property. 2023. URL: https://developer.mozilla.org/en-US/docs/Web/API/Window/innerHeight.
MDN Contributors. Window: scrollBy() Method. 2023. URL: https://developer.mozilla.org/en-US/docs/Web/API/Window/scrollBy.
MDN Contributors. Window: scrollY Property. 2023. URL: https://developer.mozilla.org/en-US/docs/Web/API/Window/scrollY.
Pylenium. Driver Commands: execute_script. 2023. URL: https://docs.pylenium.io/driver-commands/browser/execute_script.
Selenium 4 Documentation. Interacting with Web Elements. 2023. URL: https://www.selenium.dev/documentation/webdriver/elements/interactions/.
Selenium 4 Documentation. Keyboard Actions. 2023. URL: https://www.selenium.dev/documentation/webdriver/actions_api/keyboard/.
Selenium 4 Documentation. Locator Strategies: Traditional Locators. 2023. URL: https://www.selenium.dev/documentation/webdriver/elements/locators/#traditional-locators.
Selenium 4 Documentation. Mouse Actions: Offset from Element. 2023. URL: https://www.selenium.dev/documentation/webdriver/actions_api/mouse/#offset-from-element.
Selenium 4 Documentation. Working with Windows and Tabs: Execute Script. 2023. URL: https://www.selenium.dev/documentation/webdriver/interactions/windows/#execute-script.
The Modern JavaScript Tutorial. Window Sizes and Scrolling. 2024. URL: https://javascript.info/size-and-scroll-window.