8.3. Beispiel 2: Library of Congress API#
Die Library of Congress (LOC) bietet eine Reihe sehr gut dokumentierter APIs zur Abfrage von Metadaten, Dateien und Volltexten aus dem Bestand der Bibliothek. Eine davon ist die API der Sammlung US-amerikanischer historischer Zeitungen Chronicling America. Diese API werden wir in dieser Stunde kennenlernen.
Übersicht über die LOC APIs: https://guides.loc.gov/digital-scholarship/accessing-digital-materials#s-lib-ctab-26648178-2
Dokumentation zur Chronicling America API: https://libraryofcongress.github.io/data-exploration/loc.gov JSON API/Chronicling_America/README.html
Zunächst machen wir uns mit der Chronicling America API vertraut.
Verständnisfragen
Welche Daten können darüber abgefragt werden?
Was ist euer Leseeindruck? Ist die Dokumentation vollständig, ausführlich, verständlich?
An wen richtet sich die API und die Dokumentation?
Vergleicht die Dokumentationsseiten zur Chronicling America API mit der Dokumentation der Prints and Photographs Online Catalog API: https://www.loc.gov/pictures/api. An wen richtet sich dieser Dokumentationstext?
Für unser Beispiel werden wir die Volltexte zu allen Ergebnissen einer Suche nach einem Schlüsselbegriff abfragen und herunterladen. Die wichtigsten Informationen zur Verwendung der API und für unseren Anwendungsfall finden wir im Abschnitt “Definitions: API Query Parameters for Newspapers”. Zwei Hinweise sind dabei insbesondere aufschlussreich:
The easiest way to create a URL for your API query is to perform an Advanced Search at Chronicling America. If you performed an Advanced Search to create your API Query, we recommend including some of the additional query parameters. The structure of an API Query URL looks like this: https://www.loc.gov/collections/chronicling-america/?{queryparameters}&{queryparameters}?fo=json
Note: If you’re looking to download full text from the newspaper pages in a given search result, note that the full text (from OCR) is captured for each page within the “full_text” JSON field. For example: https://www.loc.gov/resource/sn83045462/1922-12-26/ed-1/?sp=22&q=clara+bow&fo=json
8.3.1. Datenqualität untersuchen#
Der letzte der beiden Hinweise gibt Aufschluss über die Qualität der Volltexte: Diese sind mithilfe von OCR-Verfahren erstellt, also mithilfe automatischer Bilderkennung (OCR steht für Optical Character Recognition). Wenn wir auf das verlinkte Beispiel klicken, öffnet sich zunächst eine JSON-Datei im Browser, die Metadaten zur angefragten Ressource als auch Links zu der Resource selbst in verschiedenen Dateiformaten enthält. Diese finden sich unter dem Schlüssel “resource” und können mithilfe der Tastenkombination Strg + F und Suche nach “full_text” gefunden werden:

Fig. 8.4 Informationen zu einer Ressource im JSON-Format abrufen#
Ein Klick auf die unter “fulltext_file” verlinkte Ressource öffnet ein weiteres JSON-Dokument, das den eigentlichen Volltext enthält:
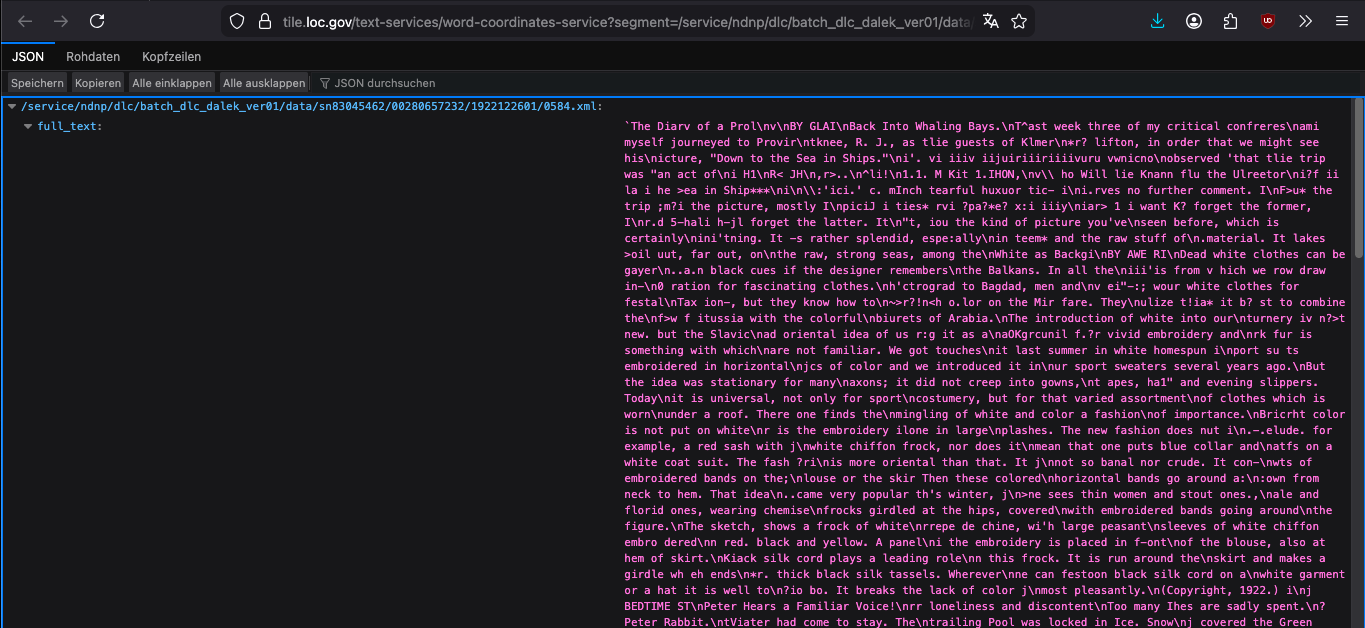
Fig. 8.5 Mithilfe von OCR erstellter Volltext einer Ressource, inkl. OCR-Fehler#
Note
JSON im Browser ansehen
Firefox stellt JSON-Dateien im Browser sehr übersichtlich dar. Das ist aber nicht bei allen Browsern der Fall. Zur Ansicht der JSON-Datei im Chrome Browser kann auf die Entwicklertools zurückgegriffen werden. Die Standardansicht ist nämlich sehr schwer lesbar, weil der JSON-String nicht formatiert ist. Um eine formatierte Ansicht zu erhalten, befolgt die folgenden Schritte: Entwicklertools öffnen -> “Sources”-Tab auswählen-> Link anklicken
Bevor ihr ein Skript zum Herunterladen der Daten über eine API schreibt, solltet ihr diese also vorab inspizieren und entscheiden, ob ihr die Daten in der verfügbaren Qualität zur Beantwortung eurer Fragestellung überhaupt nutzen könnt. Denn anders als der Inhalt einer Webseite, den ihr mit BeautifulSoup scraped, ist die Qualität der Daten, die Museen, Archive und Bibliotheken bereitstellen, nicht direkt einsehbar. Auch die Vollständigkeit der extrahierten Daten muss vorab abgeschätzt werden. Eine Suche nach Schlüsselbegriffen in einem Volltext, der mithilfe von OCR-Verfahren erstellt wurde, liefert beispielsweise immer nur diejenigen Zeitungen, in denen die Suchwörter auch korrekt erkannt wurden.
8.3.2. Suche formulieren#
Um herauszufinden, wie die Abfrage-URL für eine Suche nach bestimmten Schlüsselbegriffen aussehen muss, können wir also zunächst über die Suchmaske des Onlinekatalogs eine Suche formulieren: https://www.loc.gov/collections/chronicling-america/
Wir formulieren die Suche wie folgt:
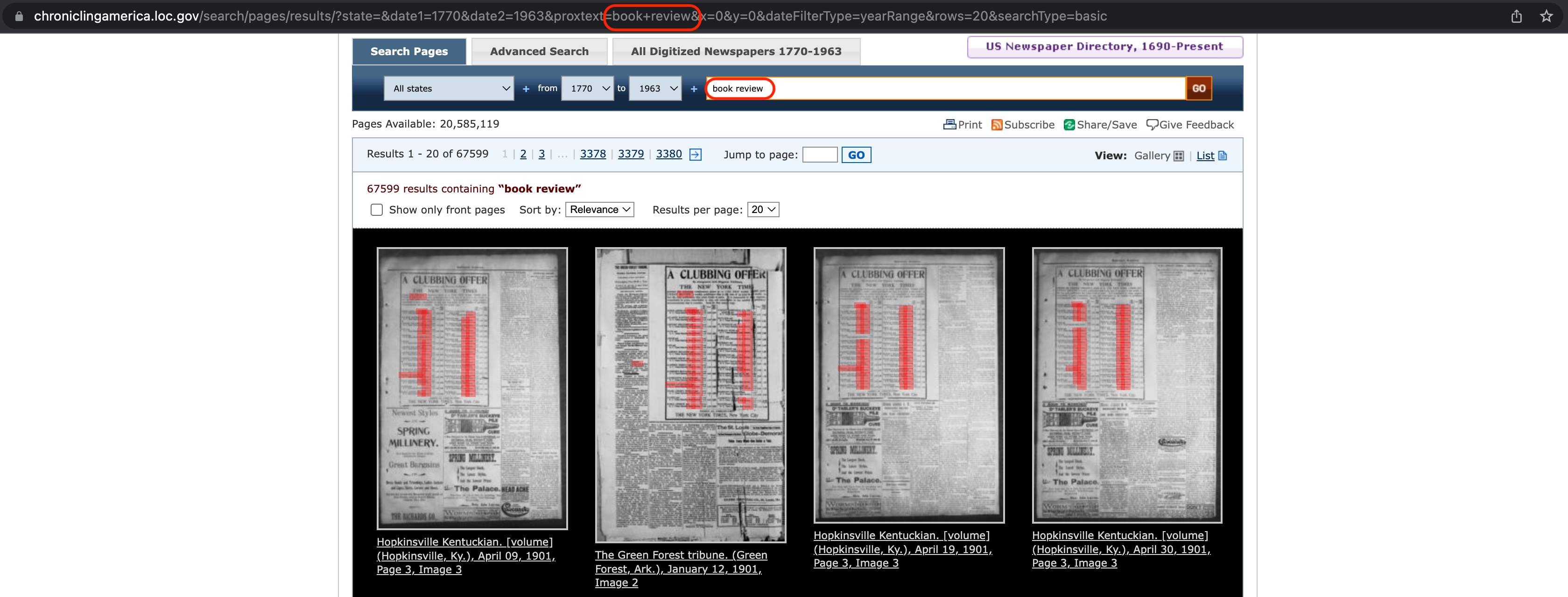
Fig. 8.6 Einfache Suche über die Suchmaske der Seite Chronicling America.#
Die Suche liefert drei Ergebnisse und vor allem eine wichtige Information zum Verhalten der Volltextsuche: Es wird nicht nur die exakte Wortkombination “book review” gefunden, sondern auch Wortkombinationen über Satzgrenzen hinweg wie “book. Review” und Wortkombinationen, in denen die Suchbegriffe vorkommen wie “book reviewed”. Auch das ist zur Einschätzung der Vollständigkeit und Qualität der extrahierten Daten wichtig.

Fig. 8.7 Ergebnisse der Suche#
Wir weiten die Suche auf 200 Jahre aus und erhalten nun 23.614 Ergebnisse. Davon werden aber nur 40 auf der ersten Seite angezeigt. Auch das ist eine wichtige Information, wie wir noch sehen werden.

Fig. 8.8 Ergebnisse der erweiterten Suche#
Verständnisfragen
Welche weiteren Parameter akzeptiert die Chronicling America API? Verwendet die Suchmaske unter dem Tab Advanced Search und beobachtet, wie verschiedene Parameter in die URL eingefügt werden.
Wie kann nur nach deutschsprachigen Texten gesucht werden?
8.3.3. Anfrage formulieren#
Mit diesen Informationen können wir nun versuchen herauszufinden, wie die Anfrage-URL aussehen muss. Wir gleichen dazu die URL, die bei unserer Suche über die Suchmaske automatisch zusammengesetzt wurde, mit der allgemeinen Struktur der Anfrage-URL aus den Dokumentationsseiten ab. Die durch die Verwendung der Suchmaske zusammengesetze URL ist https://www.loc.gov/collections/chronicling-america/?dl=page&end_date=1936-09-03&ops=PHRASE&qs=book+review&searchType=advanced&start_date=1736-09-03. Die allgemeine Form ist dagegen https://www.loc.gov/collections/chronicling-america/?{queryparameters}&{queryparameters}?fo=json. Um die Anfrageparameter später bequem austauschen zu können, erstellen wir dafür Variablen und fügen die Anfrage-URL mithilfe eines F-Strings zusammen. Was die einzelnen Parameter bedeuten, können wir dem Abschnitt “Definitions: API Query Parameters for Newspapers” entnehmen. Die Variablennamen wählen wir entsprechend der Bedeutung der Parameter. Beim Umschreiben der URL fällt auf, dass der Parameter “fo=json” in unserer Suchmasken-URL nicht vorkommt. Per Default werden die Ergebnisse im HTML-Format zur Ansicht über den Browser geliefert. Wenn wir die Ergebnisse später mit requests verarbeiten wollen, dann müssen wir also hier den Parameter “fo=json” hinzufügen.
base_url = "https://www.loc.gov/collections/chronicling-america/"
display_level = "dl=page"
end_date = "end_date=1936-09-03"
search_operation = "ops=PHRASE"
query_terms = "qs=book+review"
search_type = "searchType=advanced"
start_date = "start_date=1736-09-03"
response_format = "fo=json"
request_url = f"{base_url}?{display_level}&{end_date}&{search_operation}&{query_terms}&{search_type}&{start_date}&{response_format}"
Mit dieser Struktur wird direkt deutlich, welche Suchparameter wir verwendet haben. Etwas sauberer wäre es vermutlich allerdings, wenn wir die Kürzel für die Suchparameter (dl, end_date, fo, …) direkt in den F-String einfügen und nur für die Werte Variablen definieren. Wir lassen unsere Anfrage-URL aber erst einmal so. Zunächst testen wird die Anfrage-URL, indem wir sie einfach im Browser aufrufen:
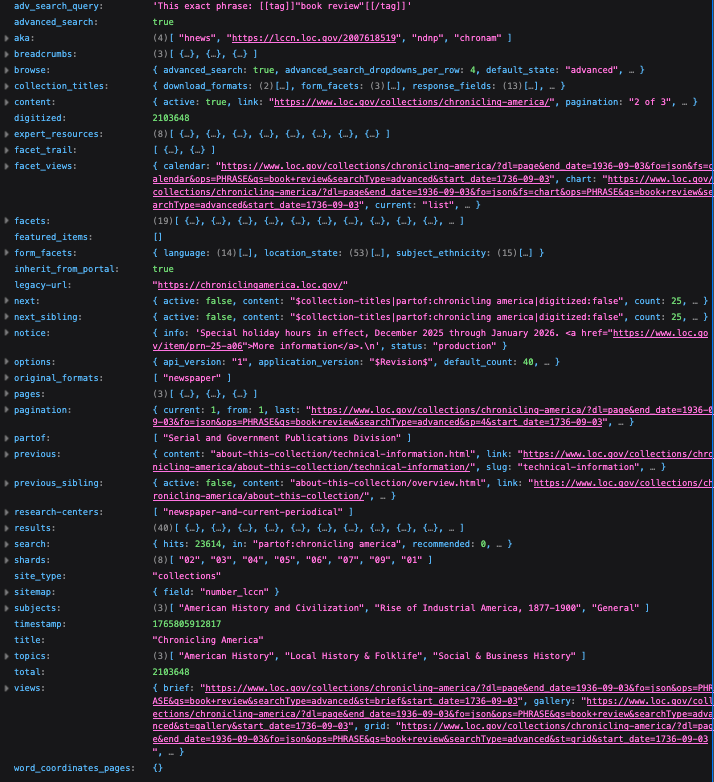
Fig. 8.9 Anfrage-URL im Browser testen#
In der überblicklichen Darstellung im Browser fällt direkt auf, dass wir nur 40 Ergebnisse bekommen haben (Schlüssel “results”). Wir stellen die Anfrage nun mithilfe von requests und überprüfen diesen Umstand:
import requests
response = requests.get(request_url)
response_dict = response.json()
search_results = response_dict["results"]
print(len(search_results))
40
Wie können wir den Rest der 23.614 Suchergebnisse erhalten? Im Abschnitt “Definitions: API Query Parameters for Newspapers” lässt sich dazu keine Information finden, aber praktischerweise bietet die Library of Congress am Ende der Seite einige Jupyter Notebooks mit Beispielabfragen, unter anderem das Notebook “Downloading Search Results from Chronicling America”: https://libraryofcongress.github.io/data-exploration/loc.gov JSON API/Chronicling_America/ChronAm-download_results.html
Dem Notebook können wir entnehmen, dass weitere Ergebnisseiten über den Schlüssel “pagination” abgerufen werden können, und zwar mit:
# if data["pagination"]["next"] is not None:
# next_url = data["pagination"]["next"]
# get_item_ids(next_url, items, conditional)
Diesen Code können wir später für unsere Zwecke anpassen.
8.3.4. Abfrage aller Volltexte mit “book review”#
Zunächst müssen wir aber eine viel dringendere Frage klären: Wir haben zwar mit unserer Anfrage-URL die Suchergebnisse im JSON-Format erhalten. Aber wie finden wir darüber die Volltexte? Die Volltexte haben wir ja über die Seiten der Ressourcen selbst bekommen, also über URLs der Form https://www.loc.gov/resource/sn83045462/1922-12-26/ed-1/?sp=22&q=clara+bow&fo=json, und auf der Ressourcenseite haben wir den Link zum Volltext selbst unter dem Schlüssel “fulltext_file” gefunden. Der Link zum Volltext hatte dabei die Form https://tile.loc.gov/text-services/word-coordinates-service?segment=/service/ndnp/dlc/batch_dlc_dalek_ver01/data/sn83045462/00280657232/1922122601/0584.xml&format=alto_xml&full_text=1&q=clara bow. Um an den Link zum Volltext zu kommen, könnten wir also die Ergebnisse unserer Suche durchgehen und für jedes Ergebnis den Link zur Ressourcenseite aufrufen, um an den Link zum Volltext zu kommen. Aber das würde eine zusätzliche Anfrage je Ergebnis erfordern. Es gibt aber noch eine zweite Möglichkeit: Unter dem Schlüssel “word_coordinates_url” steht ein sehr ähnlicher Link, der ebenfalls zu einer JSON-Datei mit dem Volltext führt, allerdings nicht zum kompletten Volltext der Ressource, sondern nur dem Ausschnitt, in dem unsere Suchbegriffe stehen: https://tile.loc.gov/text-services/word-coordinates-service?format=alto_xml&segment=%2Fservice%2Fndnp%2Fmdu%2Fbatch_mdu_galena_ver02%2Fdata%2Fsn89060092%2F00279521808%2F1911100601%2F0360.xml&q=book+review&relevant_snippet=1
Der entscheidende Unterschied ist, dass hier statt des Parameters “full_text=1” “relevant_snippet=1” steht, und dass der Link zusätzlich den Suchparameter “q=book+review” enthält. Je nachdem, in welchem Umfang der Volltext heruntergeladen werden soll, können die Parameter einfach ausgewechselt werden.
Das probieren wir erst einmal nur für die erste Ergebnisseite aus, und erweitern danach den Code so, dass die Volltexte für alle Ergebnisseiten abgefragt werden. Die folgende Schleife entfernt die Suchparameter “q=book+review” und “relevant_snippet=1” und fügt stattdessen den Parameter “full_text=1” an den Link an.
for result in search_results:
fulltext_url = result["word_coordinates_url"]
fulltext_base = fulltext_url.rsplit("&", 2)[0]
fulltext_request_url = f"{fulltext_base}&full_text=1"
Anschließend müssen wir für die neue request_url wieder eine Anfrage stellen und können dann über den Schlüssel “full_text” auf den Volltext zugreifen und diesen herunterladen.
Da es etwas unübersichtlich ist, wenn die heruntergeladenen Dateien in demselben Ordner liegen wie das Pythonskript, legen wir zunächst in unserem aktuellen Arbeitsverzeichnis (=Ordner, in dem die Jupyter Notebooks liegen) ein neues Verzeichnis an, in dem wir die Volltexte abspeichern werden:
# Neues Verzeichnis anlegen: in diesem Ordner werden die Textdateien gespeichert
# Das geht alternativ auch mit dem Paket pathlib, das ihr im Kapitel 8.2 kennengelernt habt
output_dir = os.path.join(os.getcwd(), "loc_ocr")
os.makedirs(output_dir, exist_ok=True) # exists_ok: nur erstellen, falls es noch nicht existiert
Jetzt haben wir alles vorbereitet und können die Texte herunterladen. Allerdings brauchen wir dazu noch geeignete Dateinamen für die Dateien.
for result in search_results:
fulltext_url = result["word_coordinates_url"]
fulltext_base = fulltext_url.rsplit("&", 2)[0]
fulltext_request_url = f"{fulltext_base}&full_text=1"
fulltext_dict = requests.get(fulltext_request_url).json()
dict_values= list(fulltext_dict.values())
fulltext = dict_values[0]["full_text"]
title = result["title"]
filename = f"{title}.txt"
filepath = os.path.join(output_dir, filename)
with open(filepath, "w", encoding="utf-8") as file:
file.write(fulltext)
Wie gehen wir vor, um jetzt unsere for-Schleife oben nacheinander auf alle Ergebnisseiten anzuwenden? Erinnert euch an die drei Strategien, die wir beim Scrapen der Quotes to Scrape-Website im Abschnitt “Fortsetzung BeautifulSoup” diskutiert haben. Eine andere Strategie, die wir im Zusammenhang mit der Quotes to Scrape-Website besprochen haben, war die Verwendung des “next”-Buttons. Bei dieser Strategie haben wir beim Aufruf einer Seite die URL zur nachfolgenden Seite aus dem href-Attribut des a-Elements mit dem Text “next” extrahiert und diese URL zur Formulierung der nächsten Anfrage verwendet.
Ganz ähnlich funktioniert auch die Lösung, die das vorhin besprochene Tutorial der Library Of Congress vorschlägt. Hier wurde die URL für die nächste Ergebnisseite dem Schlüssel “next” unter dem Schlüssel “pagination” entnommen (s.o.). Diese Lösung bauen wir nun in unseren Code ein:
base_url = "https://www.loc.gov/collections/chronicling-america/"
display_level = "dl=page"
end_date = "end_date=1936-09-03"
search_operation = "ops=PHRASE"
query_terms = "qs=book+review"
search_type = "searchType=advanced"
start_date = "start_date=1736-09-03"
response_format = "fo=json"
request_url = f"{base_url}?{display_level}&{end_date}&{search_operation}&{query_terms}&{search_type}&{start_date}&{response_format}"
current_url = request_url
while True:
print(current_url)
response = requests.get(current_url)
response_dict = response.json()
search_results = response_dict["results"]
for result in search_results:
fulltext_url = result["word_coordinates_url"]
fulltext_base = fulltext_url.rsplit("&", 2)[0]
fulltext_request_url = f"{fulltext_base}&full_text=1"
fulltext_dict = requests.get(fulltext_request_url).json()
dict_values= list(fulltext_dict.values())
fulltext = dict_values[0]["full_text"]
title = result["title"]
filename = f"{title}.txt"
filepath = os.path.join(output_dir, filename)
with open(filepath, "w", encoding="utf-8") as file:
file.write(fulltext)
if response_dict["pagination"]["next"] is not None:
current_url = response_dict["pagination"]["next"]
else:
break
Verständnisfragen
Wie könnte man diese Aufgabe noch lösen?
Gibt es eine alternative Vorgehensweise, an die URLs der nachfolgenden Ergebnisseiten zu kommen?
Gibt es andere Strategien, um an die Links zu den Volltexten zu gelangen?
Aber Achtung! Beim Ausführen des Codes oben gibt es nach einigen Schleifendurchläufen eine Fehlermeldung: JSONDecodeError: Expecting value: line 1 column 1 (char 0). Die Fehlermeldung entsteht dann, wenn die HTTP-Anfrage keine erfolgreiche Antwort liefert. Dieser Fall kann registriert werden, indem nach jeder Anfrage der Statuscode ausgegeben wird. Warum hat die Anfrage plötzlich keine erfolgreiche Antwort geliefert? Das liegt daran, dass wir uns nicht an die Einschränkungen der LOC gehalten haben und die HTTP-Anfrage dadurch ab einem bestimmten Punkt abgelehnt wird. Wenn wir dann versuchen, den Antwortbody mithilfe der .json()-Methode in ein Python Dictionary umzuwandeln, teilt der Python interpreter uns mit, dass das nicht möglich ist, weil wir die Methode nicht auf einen gültigen JSON-String angewendet haben.
Bei der Abfrage von sehr vielen Seiten müssen wir uns also nach den Einschränkungen der LOC richten und bestimmte Abfrageraten (Rate Limits) einhalten.
8.3.5. Rate Limits berücksichtigen und die Abfragerate steuern#
Wie wir bereits in der kurzen Einführung zu APIs besprochen haben, setzen Webseitenbetreiber:innen für gewöhnlich Grenzen für die Datenabfrage über ihre APIs fest. Manche kommunizieren diese Einschränkungen nur schriftlich in Form der Dokumentation, andere setzen sie technisch fest, sodass wiederholte Anfragen desselben Clients automatisch bei Überschreiten der erlaubten Abfragerate blockiert werden. Um dies zu verhindern und um den Server nicht mit vielen Anfragen, die schnell nacheinander gestellt werden, zu überlasten, muss der Code so geschrieben werden, dass die erlaubte Abfragerate der API eingehalten werden. Dazu können verschiedene Strategien angewandt werden, die in diesem Abschnitt vorgestellt werden.
Eine Recherche auf den Seiten der Library of Congress liefert die Seite https://www.loc.gov/apis/json-and-yaml/working-within-limits. Hier legt die LOC Einschränkungen für die der Chronicling America API übergeordnete Seite loc.gov fest. Die Chronicling America API wird zwar nicht explizit erwähnt, aber wir können vermuten, dass die Einschränkungen auch für die Chronicling America API gelten. Da etwas unklar ist, welches Limit für diese API gilt, richten wir uns nach der restriktivsten Vorgabe, nach der nur 20 Abfragen alle 10 Sekunden erlaubt sind. So sind wir in jedem Fall auf der sicheren Seite.
Wie können wir also die HTTP-Abfragen auf 20 Abfragen je 10 Sekunden einschränken? Dazu müssen wir den Code so umschreiben, dass innerhalb einer bestimmten Zeit nur eine bestimmte Anzahl an Anfragen gestellt werden.
Um die Abfragerate einzuschränken, gibt es mehrere Möglichkeiten:
Funktion
time.sleep()aus dem Paket time. Die Funktion time.sleep(x) kann in den Schleifenkörper einer for-Schleife eingefügt werden, um den nächsten Schleifendurchlauf um x Sekunden zu verzögern. Diese Methode ist einstiegsfreundlich, aber ungenau, weil die Laufzeit der Schleife selbst nicht in die Wartezeit mit einbezogen wird, sodass der nächste Schleifendurchlauf länger als notwendig verzögert wird. Auch ist es schwierig, mit dieser Strategie die Abfragerate zu kontrollieren, wenn Anfragen auf mehrere Schleifen verteilt sind wie im LOC-Beispiel.
import time
# Rate limiting mit time.sleep(): Allgemeines Schema
for i in range(1, 6):
print(i)
time.sleep(2)
1
2
3
4
5
# Rate limiting mit time.sleep(): LOC API
for result in search_results:
fulltext_url = result["word_coordinates_url"]
fulltext_base = fulltext_url.rsplit("&", 2)[0]
fulltext_request_url = f"{fulltext_base}&full_text=1"
fulltext_dict = requests.get(fulltext_request_url).json()
dict_values= list(fulltext_dict.values())
fulltext = dict_values[0]["full_text"]
title = result["title"]
filename = f"{title}.txt"
filepath = os.path.join(output_dir, filename)
with open(filepath, "w", encoding="utf-8") as file:
file.write(fulltext)
time.sleep(0.5)
Python Dekoratoren aus dem Paket ratelimit. Wesentlich effizienter und eleganter ist die Verwendung von sogenannten Python Dekoratoren bzw. Decorators. Das Paket ratelimit bietet zwei solche Dekoratoren, die dazu verwendet werden können, um zu registrieren, wie häufig eine Funktion nacheinander aufgerufen wird, und die ab einer bestimmten Anzahl wiederholter Aufrufe eine Wartepause erzwingen. Um Decorators verwenden zu können, müssen wir unsere Abfrage jedoch in eine Funktion verpacken. Das Paket ratelimit wie auch die gängigen und immer noch viel verwendeten Alternativen (z.B. ratelimiter), werden allerdings seit einigen Jahren nicht mehr maintained. Das heißt, dass der Code bereits sehr alt ist und Probleme, auf die User:innen die Entwickler:innen des Pakets aufmerksam machen, nicht mehr behoben werden. So hat zum Beispiel GitHub User:in Justin VanWinkle darauf hingewiesen, dass ratelimit in bestimmten Umständen die Abfragerate nicht zuverlässig kontrolliert.
Note
Python Dekoratoren (Decorators)
A decorator in Python is a function that accepts another function as an argument. The decorator will usually modify or enhance the function it accepted and return the modified function. This means that when you call a decorated function, you will get a function that may be a little different that may have additional features compared with the base definition.
Quelle: Michael Droscill (2017).
Dekoratoren beruhen auf einem komplexen Konzept und wir können hier nicht tiefer einsteigen, aber wenn die ein oder andere Person doch etwas tiefer einsteigen will, kann ich diese beiden Ressourcen empfehlen:
Primer on Python Decorators, https://realpython.com/primer-on-python-decorators/
Python Decorators in 15 Minutes, https://www.youtube.com/watch?v=r7Dtus7N4pI
Bei der Verwendung der Dekoratoren aus dem Paket ratelimit verwenden wir diese Anleitung von Akshay Ranganath:
Rate Limiting with Python, https://akshayranganath.github.io/Rate-Limiting-With-Python/
# wir müssen zunächst die Anaconda Einstellungen ändern, damit wir das Paket ratelimit installieren können:
# import sys
# !conda config --append channels conda-forge
# Paket ratelimit installieren
# !conda install --yes --prefix {sys.prefix} ratelimit
from ratelimit import limits, sleep_and_retry
# Rate limiting mit Python decorators: Allgemeines Schema
PERIOD_SEC = 10
CALLS_PER_PERIOD_SEC = 3 # 3 Abfragen in 10 Sekunden
@sleep_and_retry
@limits(calls=CALLS_PER_PERIOD_SEC, period=PERIOD_SEC)
def test_function(x):
print(x)
for i in range(1, 6):
test_function(i)
1
2
3
4
5
# Rate limiting mit Python decorators: LOC API
PERIOD_SEC = 10
CALLS_PER_PERIOD_SEC = 20 # 20 Abfragen in 10 Sekunden
@sleep_and_retry
@limits(calls=CALLS_PER_PERIOD_SEC, period=PERIOD_SEC)
def get_json(url):
response = requests.get(url)
return response.json()
for result in search_results:
fulltext_url = result["word_coordinates_url"]
fulltext_base = fulltext_url.rsplit("&", 2)[0]
fulltext_request_url = f"{fulltext_base}&full_text=1"
fulltext_dict = get_json(fulltext_request_url)
dict_values= list(fulltext_dict.values())
fulltext = dict_values[0]["full_text"]
title = result["title"]
filename = f"{title}.txt"
filepath = os.path.join(output_dir, filename)
with open(filepath, "w", encoding="utf-8") as file:
file.write(fulltext)
Beachtet, dass diese Funktionsdefinition sich in einem wichtigen Aspekt von der Definition der Funktion scrape_quotes() im Abschnitt “Fortsetzung BeautifulSoup” unterscheidet: Beim Aufruf der Funktion get_json() wird nur genau eine Anfrage gestellt und die Funktion wird aus einer Schleife heraus aufgerufen. Die Funktion scrape_quotes() dagegen stellt beim Aufruf mehrere Anfragen und die for-Schleife, die über die zu scrapenden URLs iteriert, befindet sich in der Funktionsdefinition selbst. Bei der Verwendung der Dekoratoren zum Rate Limiting muss darauf geachtet werden, dass die Funktion so definiert ist wie die get_json()-Funktion. Die Funktionsaufrufe können nämlich nur dann mithilfe der Funktionsaufrufe verzögert werden, wenn die Funktion auch mehrmals aufgerufen wird!
Feingranulares Rate Limiting mit dem Paket limits. Eine Alternative, die etwas mehr Code und Hintergrundwissen erfordert aber dafür auch viele Anpassungsmöglichkeiten bietet, ist das Paket limits. Das Paket ist eigentlich eher zur Implementierung von Rate Limiting in Schnittstellen und Softwaresystemen gedacht. Die Dokumentationsseiten beschreiben deswegen viele Anwendungsfälle und Konfigurationen, die recht komplex und für uns nicht relevant sind. Es kann beispielsweise zwischen verschiedenen Rate Limiting-Strategien ausgewählt werden und es kann festgelegt werden, ob die Anzahl der vergangenen Anfragen im Arbeitsspeicher oder einer externen Datenbank gespeichert werden soll. Für unsere Zwecke reicht immer der Arbeitsspeicher und die anderen Optionen können wir ignorieren. Ein möglicher Einsatz von limits zum Überwachen und Kontrollieren der Abfragerate im Rahmen von API-Abfragen könnte so aussehen:
from limits import strategies, storage, parse
# Rate limiting mit dem Paket limits: Allgemeines Schema
# Rate limit festlegen, z.B. drei Anfragen pro Sekunde. Hier geht auch z.B. "40/minute", "3/2seconds" oder "1 per second" according to https://limits.readthedocs.io/en/latest/api.html#limits.parse
rate_limit = parse("3/second")
# Speicherort festlegen: Anzahl der vergangenen Anfragen werden im Arbeitsspeicher gehalten (theoretisch ginge auch eine externe Datenbank)
memory_storage = storage.MemoryStorage()
# Strategie festlegen und Moving window rate limiter Objekt erstellen
moving_window = strategies.MovingWindowRateLimiter(memory_storage)
for i in range(1, 6):
while not moving_window.test(rate_limit, "test_requests"):
print(f"Rate limit exceeded for iteration {i}, waiting to retry...")
time.sleep(1) # alternativ 0.01 oder 0.1
moving_window.hit(rate_limit, "test_requests")
print(i)
1
2
3
Rate limit exceeded for iteration 4, waiting to retry...
4
5
# Rate limiting mit Paket limits: LOC API
rate_limit = parse("20/10seconds")
memory_storage = storage.MemoryStorage()
moving_window = strategies.MovingWindowRateLimiter(memory_storage)
for result in search_results:
fulltext_url = result["word_coordinates_url"]
fulltext_base = fulltext_url.rsplit("&", 2)[0]
fulltext_request_url = f"{fulltext_base}&full_text=1"
while not moving_window.test(rate_limit, "loc_requests"):
print(f"Rate limit exceeded, waiting to retry...")
time.sleep(0.1)
moving_window.hit(rate_limit, "loc_requests")
fulltext_dict = requests.get(fulltext_request_url).json()
dict_values= list(fulltext_dict.values())
fulltext = dict_values[0]["full_text"]
title = result["title"]
filename = f"{title}.txt"
filepath = os.path.join(output_dir, filename)
with open(filepath, "w", encoding="utf-8") as file:
file.write(fulltext)
Die Methode .test() überprüft, ob das Rate Limit bereits erreicht wurde oder nicht, also ob im angegebenen Zeitfenster (hier 10 Sekunden) bereits die erlaubte Anzahl an Anfragen gestellt wurden (hier 20). Wenn das Limit erreicht wurde, wird False zurückgegeben, ansonsten True. Die Bedingung not moving_window.test(rate_limit, "loc_requests") wird also genau dann True, wenn das Limit erreicht wurde und 20 Anfragen in 10 Sekunden gestellt wurden. In diesem Fall wird gewartet, bis genug Zeit vergangen ist und wieder Anfragen erlaubt sind. Mit der Methode .hit() wird in jedem Durchlauf der for-Schleife eine Anfrage registriert, damit sich der Zähler für die Anzahl der bisher gestellten Anfragen im Objekt memory_storage erhöht. Mehr dazu könnt ihr in den Dokumentationsseiten des Pakets limits nachlesen.
Weitere Hinweise zum Rate Limiting
Neben den drei hier vorgestellten Strategien gibt es noch weitere Möglichkeiten, die Abfragerate zu kontrollieren. Manche Schnittstellen senden bei einer nicht erfolgreichen Anfrage einen Retry-After Header mit, der angibt, wie lange der Client bis zur nächsten Anfrage warten soll. Das in diesem Blogbeitrag verlinkte Python-Skript nutzt beispielsweise den Retry-After-Header der HTTP-Antwort bei der Abfrage von Daten über die Chronicling America API.
Neben der Abfragerate können auch die Anzahl der Retries, also die Anzahl der wiederholten Anfragen beim Scheitern einer Anfrage gesteuert werden. Dabei wird häufig die Wartezeit nach jeder gescheiterten Anfrage erhöht. Wenn die Wartezeit dabei exponentiell erhöht wird, nennt man dieses Warteverhalten auch “exponential backoff” (mehr dazu hier). Wie sich eine Retry-Strategie mit requests umsetzen lässt, könnt ihr am Ende des Semesters im Kapitel “Tipps und Tricks” nachlesen.
Beachtet auch, dass es sehr oft empfehlenswert ist, auch beim einfachen Rate Limiting mit time.sleep() oder dem Rate Limiting mit dem Paket limits eine Funktion zu definieren und das Rate Limiting in dieser Funktion zu implementieren. Denn wenn an mehreren Stellen im Code Anfragen an dieselbe Schnittstelle gestellt werden, muss an jeder Stelle der Code zum Warten wiederholt werden.
Note
Konstanten (Constants)
Im Code oben verwenden wir Großbuchstaben, um die Variablen CALLS_PER_PERIOD_SEC und PERIOD_SEC zu benennen. Diese Schreibweise hat sich in Python für Konstanten etabliert, also für Variablen, deren Wert sich im Programmverlauf nicht ändert.
Note
Wahl des Dateinamens
In den Beispielen auf dieser Seite haben wir den Titel der Ressource als Dateinamen gewählt. Diese Metadaten sind aber eigentlich nicht ausreichend, um den Dateiinhalt eindeutig zu identifizieren, denn die Suchergebnisse beziehen sich nur auf eine Seite aus der angegebenen Ausgabe. Sobald unsere Suche mehr als eine Seite aus derselben Ausgabe liefert, gibt es möglicherweise mehrere Dateien mit denselben Namen, sodass Dateien möglicherweise überschrieben werden! Wie kann das Problem gelöst werden?
Lösung 1: Es werden noch mehr Metadaten, zum Beispiel die Seitenzahl, in den Dateinamen aufgenommen. Aber Achtung: Dateipfade dürfen auf den meisten Betriebssystemen höchstens 255 Zeichen lang sein. Wir müssen uns bei der Wahl der Metadaten also sicher sein, dass unter dem entsprechenden Schlüssel niemals eine sehr lange Zeichenkette steht. Wenn wir uns dem nicht sicher sein können, sollten zu lange Dateinamen mit if…else erkannt und behandelt (z.B. gekürzt) werden. Für die Validierung von Dateinamen gibt es auch ein spezialisiertes Paket, pathvalidate.
Lösung 2: Wir verwenden den Schlüssel “page_id” als Dateinamen. Die ID ist immer eine Zeichenkette der Form “sn85060004-1936-03-29-ed-1-1005”. Allerdings müssen wir uns dann auch eine effiziente Strategie, wie zu dem Suchergebnis mit der angegebenen ID weitere Metadaten abgerufen werden können, überlegen und die entsprechende Abfragelogik in Python implementieren. Ein weiteres Problem stellt die ID selbst dar, denn die Schrägstriche sind von Schrägstrichen, die Teil des Dateipfads sind, nicht zu unterscheiden. Beim Schreiben der Datei versucht der Computer also, ein Verzeichnis mit dem Namen lccn zu finden, das vermutlich nicht existiert. Um die ID verwenden zu können, können die Schrägstriche aber einfach durch Unterstriche ersetzt werden. Das geht zum Beispiel mit dem Modul re, das wir ganz am Ende des Semesters kurz besprechen werden.
Ihr seht: einen optimalen Dateinamen gibt es oft nicht. Als Faustregel solltet ihr euch merken, dass Dateinamen immer den Inhalt eindeutig indentifizieren sollten, keine Sonderzeichen wie Schrägstriche und Leerzeichen enthalten sollten, und nicht zu lang sein dürfen.
8.3.6. Quellen#
Michael Driscoll. Chapter 25 – Decorators. 2017. URL: https://python101.pythonlibrary.org/chapter25_decorators.html.
Akshay Ranganath. Rate Limiting with Python. 2021. URL: https://akshayranganath.github.io/Rate-Limiting-With-Python/.
Guido van Rossum, Barry Warsaw, and Nick Coghlan. PEP 8: Constants. 2013. URL: https://peps.python.org/pep-0008/#constants.
Geir Arne Hjelle. Primer on Python Decorators. 2023. URL: https://realpython.com/primer-on-python-decorators/.
Kite. Python Decorators in 15 Minutes. 2020. URL: https://www.youtube.com/watch?v=r7Dtus7N4pI.
Leodanis Pozo Ramos. Python Constants: Improve Your Code's Maintainability. 2022. URL: https://realpython.com/python-constants/.
Library of Congress. Chronicling America. About the Site and API. 2023. URL: https://chroniclingamerica.loc.gov/about/api/.
Library of Congress. Working Within Limits. 2023. URL: https://www.loc.gov/apis/json-and-yaml/working-within-limits.
Limits 3.14.1 Documentation. Quickstart. 2023. URL: https://limits.readthedocs.io/en/stable/quickstart.html.
Limits 3.14.1 Documentation. Rate Limiting Strategies. 2023. URL: https://limits.readthedocs.io/en/stable/strategies.html.