5 Textanalyse I: Korpus, Tokens, Daten und Dateien
5.1 Was sind eigentlich Daten?
Most of my colleagues in literary and cultural studies would not necessarily speak of their objects of study as “data.” If you ask them what it is they are studying, they would rather speak of books, paintings and movies; of drama and crime fiction, of still lives and action painting; of German expressionist movies and romantic comedy. […] However, in the humanities just as in other areas of research, we are increasingly dealing with “data.”
Quelle: Christoph Schöch (2013). Clean? Smart? Messy? Data in the Humanities, in: Journal of Digital Humanities 2, no. 3
In den Geisteswissenschaften wird der Begriff “Daten” kaum verwendet, aber in den Digital Humanities allgemein und besonders in der Textanalyse sind “Daten” allgegenwärtig. Auch in diesem Seminar haben wir bereits “Datentypen” und “Datenstrukturen” kennengelernt. Aber was sind denn eigentlich geisteswissenschaftliche Daten? Und was sind Textdaten, oder anders formuliert: Wie wird eine Textdatei zu Daten, die in R repräsentiert, bearbeitet und ausgewertet werden können? Um uns dem Begriff anzunähern, betrachten wir zwei Passagen aus Christoph Schöchs Aufsatz “Big? Smart? Clean? Messy? Data in the Humanities” (2013).
Schöch fasst zunächst Diskussionen zur Begriffsbestimmung in den Digital Humanities zusammen:
Some practitioners of digital humanities, notably Joanna Drucker, have argued that the term “data” is actually inadequate. And indeed, the term’s etymology seems problematic in the context of the humanities: it comes from the Latin datum, which means “that which is given.” This means it carries with it the meaning of an observer-independent fact which cannot be challenged in itself. Johanna Drucker prefers to speak of “capta” instead of data, literally “that which has been captured or gathered”, underlining the idea that even the very act of capturing data in the first place is oriented by certain goals, done with specific instruments, and driven by a specific attention to a small part of what could have been captured given different goals and instruments. In other words, capturing data is not passively accepting what is given, but actively constructing what one is interested in.
Und schlägt dann eine eigene Definition für den Begriff “Daten” vor:
Data in the humanities could be considered a digital, selectively constructed, machine-actionable abstraction representing some aspects of a given object of humanistic inquiry.
Geisteswissenschaftliche Daten sind also erst einmal ganz allgemein “digitale Abstraktionen”, die Aspekte eines (Forschungs-)Objekts repräsentieren. Sie sind dabei nicht einfach “gegeben”, sondern sie werden aktiv von Forscher:innen im Hinblick auf eine bestimmte Fragestellung konstruiert und mithilfe von ganz konkreten Methoden nach bestimmten Regeln gesammelt.
Je nachdem, wie die so gesammelten Daten organisiert sind, kann zwischen strukturierten und unstrukturierten Daten unterschieden werden:
Structured data is typically held in a database in which all key/value pairs have identifiers and clear relations and which follow an explicit data model. Plain text is a typical example of unstructured data, in which the boundaries of individual items, the relations between items, and the meaning of items, are mostly implicit. Data held in XML files is an example of semi-structured data, which can be more or less strictly constrained by the absence or presence of a more or less precise schema.
Zusätzlich kann zwischen Daten und Metadaten unterschieden werden:
[…] “data” refers to the part of a file or dataset which contains the actual representation of an object of inquiry, while the term “metadata” refers to data about that data: metadata explicitly describes selected aspects of a dataset, such as the time of its creation, or the way it was collected, or what entity external to the dataset it is supposed to represent.
Aber was sind denn ganz konkret die Daten, mit denen wir bei der Textanalyse zu tun haben? Sind diese Daten strukturiert, unstrukturiert oder semi-strukturiert? Und was sind “Metadaten” von Textdaten?
5.2 Korpus, Tokens und Types
In der Übungsaufgabe zur heutigen Sitzung habt ihr euch bereits die Begriffe “Korpus”, “Token”, “Type” und “Document-Term-Matrix” erarbeitet, und seid dabei zu folgenden Definitionen gelangt:
- Korpus: Texte oder andere Objekte, die auf eine bestimmte Weise mit einem Forschungsziel oder im Hinblick auf einen bestimmten Aspekt gesammelt wurden. Bei Textkorpora kann das beispielsweise die Textsorte, Epoche oder Autor:in sein (s. forText). “Eine nach bestimmten Regeln geordnete und nach Auswahlkriterien zusammengestellte Sammlung von Texten” (Riebling 2019, S. 152).
- Tokens: Vorkomnisse von Wörtern oder Äußerungen in Texten (s. forText)
- Types: Typen von Wörtern oder Äußerungen in Texten (s. forText)
- Document-Term-Matrix (oder Document-Feature-Matrix): Eine numerische Repräsentation eines Textkorpus als Matrix, bei der jede Zeile einem Satz oder Text (“document”) entspricht, und jede Spalte einem Token oder Type (“term” bzw. “feature”). In den Zellen wird angezeigt, ob bzw. wie häufig jedes Token oder Type in einem Dokument vorkommt (s. Jünger/Gärtner 2023; Van Atteveldt 2022).
Achtung
Es heißt “das Korpus” und nicht “der Korpus”.
Wie verhalten sich also die Begriffe “Korpus”, “Tokens” und “Types” zum Begriff der Daten?
Textkorpora liegen zunächst als Dateien vor, z.B. als PDF-Dateien, XML-Dateien oder Plaintext-Dateien. Diese Dateien selbst sind noch keine Daten. Damit der Text in R analysiert werden kann, muss der Computer den Text aus den Dateien einlesen können, und das geht nur, wenn der Text in maschinenlesbarer Form vorliegt. Plaintext-Dateien (also Dateien mit der Dateiendung .txt) und XML-Dateien (lernen wir noch) sind zum Beispiel immer maschinenlesbar, während ein Foto eines Textes oder ein Text, der eingescant und als PDF-Datei gespeichert wurde, nicht maschinenlesbar sind. Um solche Texte maschinenlesbar zu machen, müssen komplexe Verfahren der optischen Zeichenerkennung (OCR) angewandt werden. In diesem Seminar werden wir ausschließlich mit bereits maschinenlesbaren Texten arbeiten, und zwar mit Plaintext- und XML-Dateien.
Ein Korpus kann direkt aus Plaintext- oder XML-Dateien in R eingelesen werden. Beim Einlesen von Plaintext-Dateien können Metadaten zu jedem Text aus dem Dateinamen extrahiert werden, zum Beispiel der Name der Autor:in, das Publikationsjahr und der Titel eines Textes. Der Text selbst repräsentiert die eigentlichen Daten, die noch unstrukturiert vorliegen: In einem Korpus von Texten verschiedener Autor:innen können wir zum Beispiel davon ausgehen, dass sich das verwendete Vokabular unterscheidet oder dass vielleicht ein:e Autor:in im Schnitt kürzere Sätze schreibt als ein:e andere:r, aber diese Merkmale sind implizit und liegen nicht in strukturierter Form vor. Welche Merkmale oder Aspekte uns interessieren, hängt wiederum von der Auswahl der Texte und unserer Forschungsfrage ab; wir finden also diese Merkmale nicht einfach als “Daten” vor. Wenn Texte dagegen aus XML-Dateien eingelesen werden, ist der Text bereits vor dem Einlesen teilweise strukturiert (oder “semi-strukturiert”) und mit Metainformationen versehen. Darauf kommen wir in der Sitzung zu XML-TEI noch einmal zurück.
Unicode und Encodings
Text wird im Computer eigentlich als Abfolge von Zeichen abgebildet, und jedes Zeichen wird im Computer durch eine Zahlenfolge repräsentiert. Wie genau diese Folge aussieht, hängt davon ab, welche Kodierung (Encoding) dazu verwendet wird. Eine der ersten Kodierungen war ASCII, mit der allerdings nur Zeichen aus dem lateinischen Alphabet repräsentiert werden können. Heutzutage gibt es mit Unicode einen international anerkannten Standard-Zeichensatz. Dieser Zeichensatz ordnet nicht nur allen Zeichen im lateinischen Alphabet, sondern allen Zeichen in allen Schriftsprachen und sogar Symbolen wie Emojis einen einzigartigen Zahlenwert zu. Solche Unicode-Zahlenwerte heißen “Codepunkte”. Zeichenketten, die als Unicode-Codepunkte repräsentiert werden, können mithilfe von Kodierungen wie UTF-8 in Zahlenfolgen, die nur aus Nullen und Einsen bestehen (Bytes) umgewandelt werden.
Beim Einlesen und Speichern von Dateien muss in R auf die Wahl des richtigen Encodings geachtet werden, insbesondere beim Umgang mit nicht-lateinischen Schriften. Das werden wir später in der Praxis genauer betrachten.
Text wird im Computer also als Abfolge von Zeichen abgebildet. In R ist eine Abfolge von Zeichen ein Objekt vom Typ character. Wie wir bereits gesehen haben, kann aber auf Zeichen in R nicht einzeln zugegriffen werden. Verschiedene Wörter bilden dieselbe Zeichenkette und können nicht unterschieden werden. Deswegen wird Text tokenisiert: Das Tokenisieren, also das Zerlegen des Textes in sinnvolle Einheiten (Tokens), ermöglicht zum einen den Zugriff auf einzelne Wörter oder Äußerungen im Text, und zum anderen deren quantitative Auswertung.
Was genau eine Einheit (also ein Wort oder eine Äußerung) in einem Text bildet, ist jedoch kontextabhängig: In einem Korpus von Social Media Posts zum Beispiel hat das Rautezeichen eine besondere Bedeutung und Raute-Wortkombinationen wie #digitalhumanities bilden ein Token. Aber das Rautezeichen kann in einem anderen Kontext etwas ganz anderes bedeuten; zum Beispiel kommt es auch in URLs vor, um Ankerelemente zu kennzeichnen. Ein Punkt kann das Ende eines Satzes kennzeichnen, oder er ist Teil eines Titels wie Prof. oder Mr. Nach welchen Regeln ein Text tokenisiert werden soll und was dabei als Token gezählt wird, hängt nicht zuletzt auch von der Forschungsfrage ab. In seinem Werk “Enumerations: Data and Literary Study” hat Andrew Piper beispielsweise ein ganzes Kapitel einer quantitativen Analyse der Bedeutung von Satzzeichen in der Lyrik gewidment: Ein Satzzeichen ist für eine solche Analyse offensichtlich ein sehr wichtiges Token. In anderen Analysen spielen Satzzeichen dagegen gar keine Rolle. Schon beim Tokenisieren treffen Forscher:innen also aktive Entscheidungen, wie Textdaten strukturiert und repräsentiert werden: sie konstruieren die Daten und finden sie nicht einfach vor.
In R kann ein tokenisierter Text als spezieller Vektor dargestellt werden, bei dem jedes Token ein Element bildet. Im quanteda-Kontext wird dazu ein tokens-Objekt verwendet: Ein tokens-Objekt bildet ein tokenisiertes Korpus im Grunde als eine Liste von Vektoren ab, wobei jedes Element der Liste einem Dokument aus dem Korpus entspricht. Die Reihenfolge der Tokens ist für alle Texte in einem tokens-Objekt beibehalten. Es handelt sich dabei lediglich um eine Repräsentation von Texten als Abfolge von Tokens (also als “string of words”).
Ein weiterer Abstraktionsschritt ist die numerische Repräsentation von Texten als Ansammlung von Tokens ohne festgelegte Reihenfolge (also als “bag of words”). Wie wir bereits gesehen haben, kann eine Document-Term-Matrix (DTM) verwendet werden, um ein Korpus auf diese Weise darzustellen. Die Textdaten liegen als DTM strukturiert vor: Die Beziehung zwischen Dokumenten und Tokens (oder Types) ist durch die Spalten und Zeilen klar definiert und wird durch die Angabe, ob bzw. wie oft jedes Token vorkommt, zusätzlich quantifiziert.
5.3 Überblick: Textanalyse mit Quanteda
Im Kapitel IV: Funktionen und Pakete haben wir bereits das Paket quanteda kennengelernt. Das Paket quanteda bietet eine Vielzahl Funktionen zur quantitativen Analyse von Text sowie spezialisierte Datenstrukturen und sogar Datensätze.
Bevor wir ganz praktisch in die Textanalyse mit quanteda einsteigen, verschaffen wir uns einen theoretischen Überblick über das Vorgehen:
Zur Textanalyse mit quanteda wird gewöhnlich zunächst ein Korpus aus Plaintext-Dateien im RStudio eingelesen. Die Texte werden dann mithilfe verschiedener Funktionen in quanteda-Datenobjekte umgewandelt: In ein quanteda corpus-Objekt, tokens-Objekt und/oder in eine Document Feature Matrix (DFM). Für verschiedene Arten von Analysen verwendet man verschiedene Arten von Objekten. Grundsätzlich wird dabei zwischen Bag-of-Words und String-of-Words Methoden unterschieden, also zwischen Methoden, bei denen die Reihenfolge der Tokens beibehalten wird (String-of-Words) und jenen, bei denen die Reihenfolge keine Rolle spielt (Bag-of-Words). Bei String-of-Words Methoden werden Texte also als Abfolge von Wörtern behandelt, und bei Bag-of-Words-Methoden als Ansammlung von Wörtern. Da ein tokens-Objekt in quanteda Texte als Abfolge von Wörtern repräsentiert, werden für Analysen, bei denen die Reihenfolge der Tokens eine Rolle spielt, quanteda tokens-Objekte verwendet. Wenn die Reihenfolge keine Rolle spielt, wird eine DFM verwendet, da eine DFM Texte als Ansammlung von Wörtern repräsentiert.
Die folgende Überblicksdarstellung illustriert, welche quanteda-Objekte für welche Analysemethoden verwendet werden können:
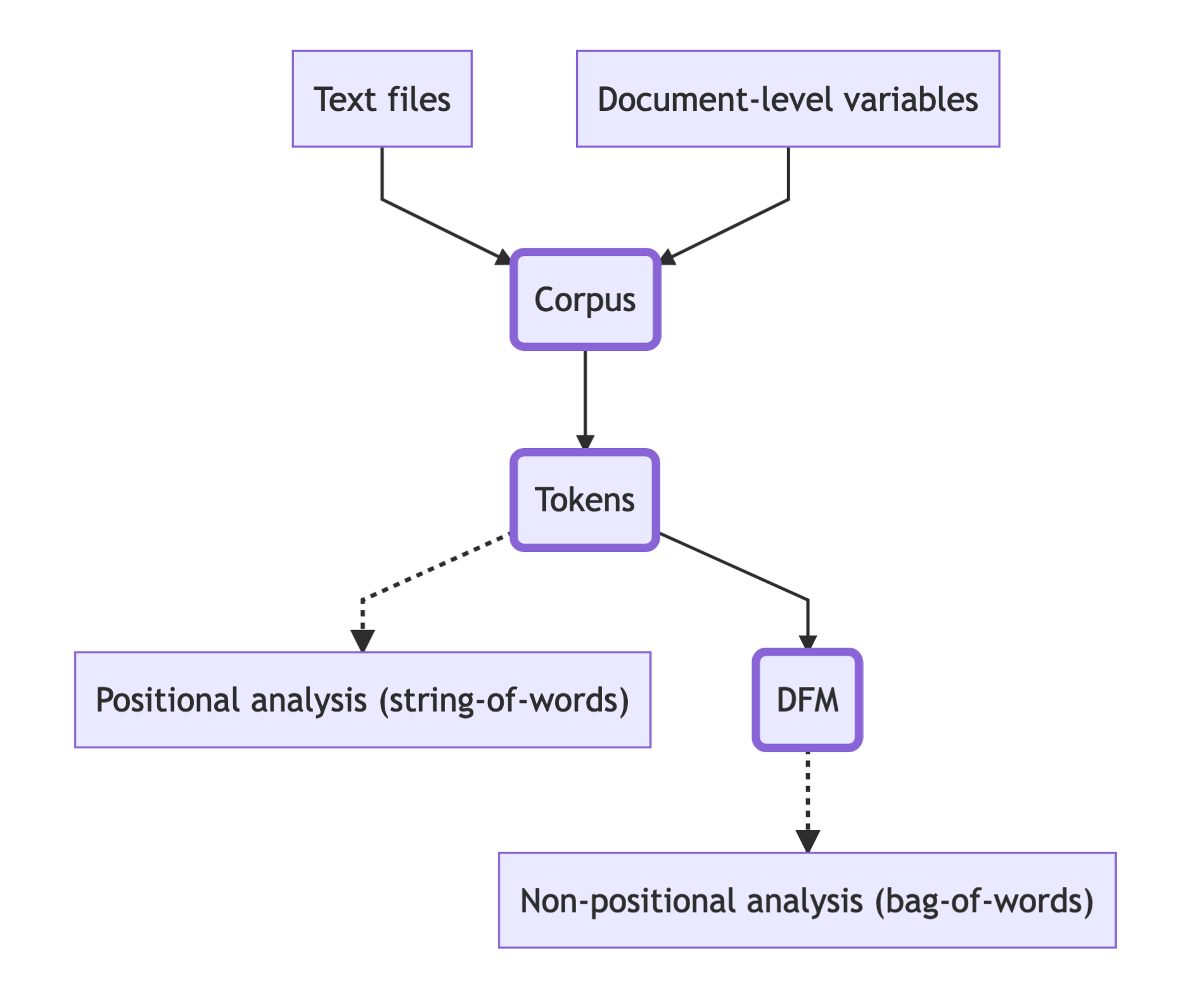
Um auf die quanteda-Funktionen zugreifen zu können, müssen neben dem Paket quanteda weitere Pakete installiert werden. Weil die Pakete alle zusammengehören, werden diese “Unterpakete” auch Module genannt:
- quanteda: contains all of the core natural language processing and textual data management functions
- quanteda.textmodels: contains all of the text models and supporting functions, namely the textmodel_*() functions
- quanteda.textstats: statistics for textual data, namely the textstat_*() functions
- quanteda.textplots: plots for textual data, namely the textplot_*() functions
In der heutigen Stunde werden wir die grundlegenden quanteda-Funktionen und quanteda-Datenstrukturen kennenlernen. Als Beispiel dient uns ein Korpus deutschsprachiger belletristischer Texte aus dem späten 19. und frühen 20. Jahrhundert. Zunächst werden wir das Korpus einlesen, danach werden wir quanteda corpus- und tokens-Objekte und zuletzt eine DFM erstellen.
5.4 Textdateien einlesen
Um Dateien in R einzulesen, muss zuerst das Arbeitsverzeichnis gesetzt werden. Das heißt, dass wir dem Computer mitteilen müssen, in welchem Ordner auf unserem Computer sich die Dateien befinden, die wir einlesen wollen. Um das Arbeitsverzeichnis zu setzen, gibt es mehrere Möglichkeiten:
# Arbeitsverzeichnis setzen
setwd("/Users/gast/R-Seminar") # Setzt hier euren eigenen Pfad ein
# Backslashes für Windows:
# setwd("C:\Users\gast\R-Seminar")Alternativ kann das Arbeitsverzeichnis auch über den Tab “Files” im Fenster unten rechts gesetzt werden. Navigiert euch dazu erst in den gewünschten Ordner, klickt dann auf “More” und “Set As Working Directory”.
Wenn wir das Arbeitsverzeichnis gesetzt haben, können wir die Dateien einlesen. Auch hier gibt es mehrere Möglichkeiten: Zum Einlesen von Dateien können entweder R-Basisfunktionen verwendet werden oder Funktionen aus einem R Paket. Die Entwickler:innen von quanteda empfehlen, zum Einlesen eines Textkorpus die Funktion readtext() aus dem Paket readtext zu verwenden. Beim Einlesen der Texte mithilfe der readtext()-Funktion können direkt Metadaten aus den Dateinamen extrahiert werden, im Beispiel unten Autor:innennamen, Titel und Publikationsjahre der Texte. Diese Metadaten auf Dokumentenebene heißen im readtext- und quanteda-Kontext dann “docvars”. Wir vergleichen im Folgenden die verschiedenen Einlesefunktionen:
# 1. R base Funktionen - Beispiele
# multi-purpose Funktion "scan"
kafka_1 <- scan("kafka_verwandlung_1915.txt", what="character", encoding = "UTF-8", sep="\n")
# Alternative nur für Textdateien: readLines
kafka_2 <- readLines("kafka_verwandlung_1915.txt")
# 2. Paket readtext
install.packages("readtext")
library(readtext)
# einen Text einlesen und einer Variable zuweisen
kafka_3 <- readtext::readtext("kafka_verwandlung_1915.txt")
# zwei Texte einlesen
kafka_3 <- readtext::readtext(c("kafka_verwandlung_1915.txt", "kafka_prozess_1925.txt"))
kafka_3
# alle Texte in einem Ordner einlesen
ein_korpus <- readtext("korpus/*.txt")
ein_korpus
# Texte in einem Unterordner einlesen
noch_ein_korpus <- readtext("Unterordner/*.txt") # oder /Unterordner/*.txt
noch_ein_korpus
# Texte in einem Ordner einlesen und Metadaten aus den Dateinamen extrahieren
ger_texte <- readtext("korpus/*.txt", docvarsfrom = "filenames", dvsep = "_", docvarnames = c("Autor_in", "Titel", "Jahr"), encoding = "UTF-8")
ger_texte
# Vergleich
typeof(kafka_1) #scan
typeof(kafka_2) #readLines
typeof(kafka_3) #readtext
class(kafka_3)Beachtet, dass die Funktion typeof() angibt, wie ein Objekt intern in R gespeichert ist. Das muss immer eine der grundlegenden R Datenstrukturen sein, die wir in Kapitel II kennengelernt haben. Die Funktion class() dagegen gibt an, wie ein Objekt in R behandelt wird: Das heißt, auch wenn manche Pakete ihre eigenen Datenstrukturen definieren und festlegen, welche Eigenschaften diese haben und Funktionen darauf angewendet werden können, müssen diese Datenstrukturen irgendwie wieder als R Datenstrukturen interpretiert werden, damit sie gespeichert werden können. Während das Objekt kafka_3 also intern als Liste gespeichert ist, handelt es sich dabei eigentlich um einen Dataframe, und ganz genau gesagt um ein readtext-Objekt. Das Objekt teilt also Eigenschaften mit R Dataframes, aber es hat auch weitere spezielle Eigenschaften von readtext-Objekten, und es gibt Funktionen, die nur auf genau diese Art von Objekt angewendet werden können.
Verständnisfragen:
- Was ist der Unterschied zwischen den Objekten, die wir mit
readLines(),scan()undreadtext()erstellt haben? - Welche anderen Unterschiede könnt ihr den R-Dokumentationsseiten zu den Funktionen entnehmen?
Bereits nach dem Einlesen können wir uns einen Überblick über das Korpus verschaffen. Dabei können auch die beim Einlesen aus den Dateinamen extrahierten Metadaten zu den einzelnen Texten abgefragt werden.
5.5 Quanteda corpus-Objekte
Ein Quanteda corpus-Objekt enthält die eingelesenen Texte selbst, sowie Metadaten auf Dokument- und Korpusebene.
library(quanteda)
# quanteda-Korpusobkjekt erstellen
ger_korpus <- quanteda::corpus(ger_texte)
ger_korpusDie Funktion str() kann verwendet werden, um einen Überblick über die Struktur des Objekts zu erhalten. Da ein Quanteda corpus-Objekt neben den Texten selbst auch Metadaten enthält, gibt die str()-Funktion einen Überblick über alle Metadaten. Die Metadaten der einzelnen Dokumente (z.B. Dateinamen, ggf. mithilfe der readtext-Funktion extrahierte docvars) können unter attr(*, "docvars") eingesehen werden. attr(*, "meta") beschreibt dagegen alle Metadaten auf Korpusebene (z.B. Informationen zu Ort und Zeit der Erstellung des corpus-Objekts).
Mit der Funktion summary() können Informationen zu den Texten selbst abgerufen werden. Die Funktion berechnet für jeden Text in einem Korpus die Anzahl der Tokens, der Types und der Sätze und bietet so einen ersten Überblick über das Korpus.
# Weitere Informationen abrufen mit der summary()-Funktion
ger_info <- summary(ger_korpus, 109)
ger_info
?summaryVerständnisfrage:
- Warum haben wir der
summary()-Funktion beim Aufruf 109 als zusätzliches Argument übergeben?
Die summary()-Funktion gibt einen Dataframe zurück. Es können deswegen alle Zugriffsoperationen und Funktionen auf das Objekt ger_info angewendet werden, die auf Dataframes angewendet werden können:
# Minimum und Maximum der Spalten Jahr und Tokens
range(ger_info$Jahr)
range(ger_info$Tokens)
# Anzahl der verschiedenen Autor:innen
length(unique(ger_info$Autor_in))
# Gesamtzahl der Tokens im ger_korpus Korpus
sum(ger_info$Tokens)
# Titel des Textes mit den meisten Tokens
ger_info$Titel[ger_info$Tokens == max(ger_info$Tokens)]
# Autor:in des Textes mit den meisten Tokens
ger_info$Autor_in[ger_info$Tokens == max(ger_info$Tokens)]
# Titel des Textes mit einer Tokenanzahl zwischen 250000 und 300000
ger_info$Titel[ger_info$Tokens >= 250000 & ger_info$Tokens <= 300000]Mithilfe von R-base-Funktionen können Daten auch visualisiert werden, zum Beispiel als Histogramm (Funktion hist()) oder als Boxplot (Funktion boxplot()). Die R-base-Funktionen sind jedoch nur für sehr einfache Visualisierungen geeignet. Mehr Anpassungsmöglichkeiten und ein moderneres Design bietet das auf die Datenvisualisierung spezialisierte Paket ggplot2, das wir in der übernächsten Stunde kennenlernen werden.
# Histogramm: Anzahl der Tokens je Text
hist(ger_info$Tokens)
# Boxplot: Median, mittlere 50% (Interquartilsabstand), Ausreißer
boxplot(ger_info$Tokens)Verständnisfragen:
- Wie kann man diese Funktionen anpassen? Schaut in die R-Hilfeseiten
- Fügt eine Beschriftung für die x und y-Achsen hinzu, indem ihr der Funktion die zusätzlichen Argumente ylab=“…” und xlab=“…” übergebt.
- Fügt einen Titel mithilfe des Arguments main=“…” hinzu.
- Was sind die drei längsten Werke in unserem Korpus?
Oft ist bei der Textanalyse der Vergleich zwischen verschiedenen Teilkorpora oder Unterkorpora von Interesse, beispielsweise, wenn die Texte verschiedener Autor:innen verglichen werden sollen. Ein Teilkorpus kann unkompliziert nach dem Einlesen der Texte erstellt werden:
# Teilkorpus aus Kafka-Texten erstellen mit R Base-Funktionen
length(which(ger_korpus$Autor_in == "kafka"))
which(ger_korpus$Autor_in == "kafka") # gibt aus 39 40 41 42 43 44 45 46 47 48 49
ger_korpus[39:49]
# Teilkorpus aus Kafka-Texten erstellen: the quanteda way
kafka_korpus <- corpus_subset(ger_korpus, Autor_in == "kafka")
kafka_korpus
# Teilkorpus erstellen und Korpusinformationen zusammenfassen in einer Zeile
kafka_summary <- summary(corpus_subset(ger_korpus, Autor_in == "kafka"))
# Wir können auch stattdessen den Dataframe ger_info nach Kafka-Texten filtern:
kafka_summary <- ger_info[ger_info$Autor_in == "kafka",]
# Wie viele Texte umfasst das Kafka-Korpus?
View(kafka_summary) 5.6 Quanteda tokens-Objekte
Ein Quanteda tokens-Objekt bildet ein tokenisiertes Korpus als eine Liste von Vektoren ab, wobei jedes Element der Liste einem Dokument aus dem Korpus entspricht. Die Reihenfolge der Tokens ist für alle Texte in einem tokens-Objekt beibehalten.
# quanteda-Tokensobjekt erstellen
ger_toks <- quanteda::tokens(ger_korpus)
# Print-Funktion muss für quanteda-Objekte angepasst werden: http://quanteda.io/reference/print-quanteda.html
print(ger_toks[1]) # wird nicht komplett angezeigt
print(ger_toks[1], max_ntoken = 200) # 200 Tokens anzeigenAuch ein tokens-Objekt kann mithilfe der Funktion str() untersucht werden. Quanteda tokens-Objekte enthalten neben den Tokens selbst dieselben Metadaten wie quanteda corpus-Objekte.
Und genau wie von einem Quanteda corpus-Objekt lässt sich auch eine Auswahl bestimmter Texte von einem tokens-Objekt bilden:
5.7 Quanteda DFM-Objekte
Für die meisten Analysemethoden wird eine sogenannte Document-Feature-Matrix (DFM) verwendet. Wie wir bereits gesehen haben, ist eine DFM eine Matrix, deren Spalten “Features” und deren Zeilen Dokumente repräsentieren. In unserem Fall sind die Features Tokens und die Dokumente sind die Texte des Korpus.
5.8 Daten schreiben
Alle Objekte, die wir bisher erstellt haben, existieren nur in unserer RStudio Umgebung. Es gibt verschiedene Möglichkeiten, diese Objekte zu speichern. Wenn Objekte in einem eigenen Ordner (=“Verzeichnis”) gespeichert werden sollen, kann dieser direkt aus R heraus erstellt werden:
# Neuen Ordner erstellen: falls bereits ein Ordner "output" existiert, wird dieser gelöscht
unlink("output", recursive = T)
dir.create("output")
setwd(paste0(getwd(), "/output"))
getwd()Tabellarische Daten (Dataframes) können zum Beispiel in csv-Dateien gespeichert werden:
# Dataframe in csv-Datei schreiben
write.csv2(ger_info, "ger_info.csv")
# Können wir verhindern, dass die Zeilenindizes als eigene Spalte gespeichert werden?
?write.csv2
# Ja, mit dem Parameter row.names:
write.csv2(ger_info, "ger_info.csv", row.names=FALSE)Objekte, die für die Weiterverarbeitung in R gedacht sind, wie zum Beispiel quanteda tokens-Objekte oder auch der ger_info Dataframe, können außerdem in R-internen Datenformaten gespeichert werden:
# R-interne Datenformate: R Objekte speichern und laden
# rds: Ein Objekt in einer Datei speichern
saveRDS(ger_info, file="ger_info.rds")
saveRDS(ger_toks, file="ger_toks.rds")
# RData und rda : Mehrere Objekte in einer Datei speichern
save(kafka_1, kafka_2, kafka_3, file="uebung.rda")
save(kafka_1, kafka_2, kafka_3, file="uebung.RData")RDS-, RDA- und RData-Dateien können später eingelesen werden mit:
ger_info <- readRDS(file="ger_info.rds")
ger_toks <- readRDS(file="ger_toks.rds")
load(file="uebung.rda")
load(file="uebung.RData")Und csv-Dateien könne eingelesen werden mit:
Um Änderungen zu speichern, die wir ggf. an den eingelesenen Texten vorgenommen haben, können wir diese einfach in eine neue Textdatei schreiben:
Quellen
- Schöch, Christoph (2013). Clean? Smart? Messy? Data in the Humanities, in: Journal of Digital Humanities 2, no. 3, http://journalofdigitalhumanities.org/2-3/big-smart-clean-messy-data-in-the-humanities/.
- ForText (2016), Glossar: Type/Token, https://fortext.net/ueber-fortext/glossar/type-token.
- ForText (2016), Glossar: Korpus, https://fortext.net/ueber-fortext/glossar/korpus.
- Jünger, J. and Gärtner, C. (2023). Computational Methods für die Sozial- und Geisteswissenschaften. Kapitel 9: Textanalyse, S. 356-359, https://doi.org/10.1007/978-3-658-37747-2_9.
- Riebling, Jan Rasmus (2019). Methode und Methodologie quantitativer Textanalyse. Kapitel 5: Text und Token, S. 125-160, https://d-nb.info/1188242121/34.
- Lukes, David (2016). How Computers Handle Text: A Gentle but Thorough Introduction to Unicode, https://dlukes.github.io/unicode.html.
- Van Atteveldt, Wouter, Trilling, Damian und Arcila Calderón, Carlos (2022). Computational Analysis of Communication. Chapter 9: Processing Text, https://cssbook.net/content/chapter09.html.
- Van Atteveldt, Wouter, Trilling, Damian und Arcila Calderón, Carlos (2022). Computational Analysis of Communication. Chapter 5.2.2: Encodings and Dialects, https://cssbook.net/content/chapter05.html#sec-encodings.
- Quanteda-Website: https://quanteda.io/
- Quanteda Tutorials: https://tutorials.quanteda.io/
- Quanteda Quick Start Guide: https://quanteda.io/articles/quickstart.html