Über diesen Kurs
Warum R?
Was ist R überhaupt?
R Thirst Traps
Seminarplan
Lernziele
Organisatorisches
Hilfe!!
Installation und Setup
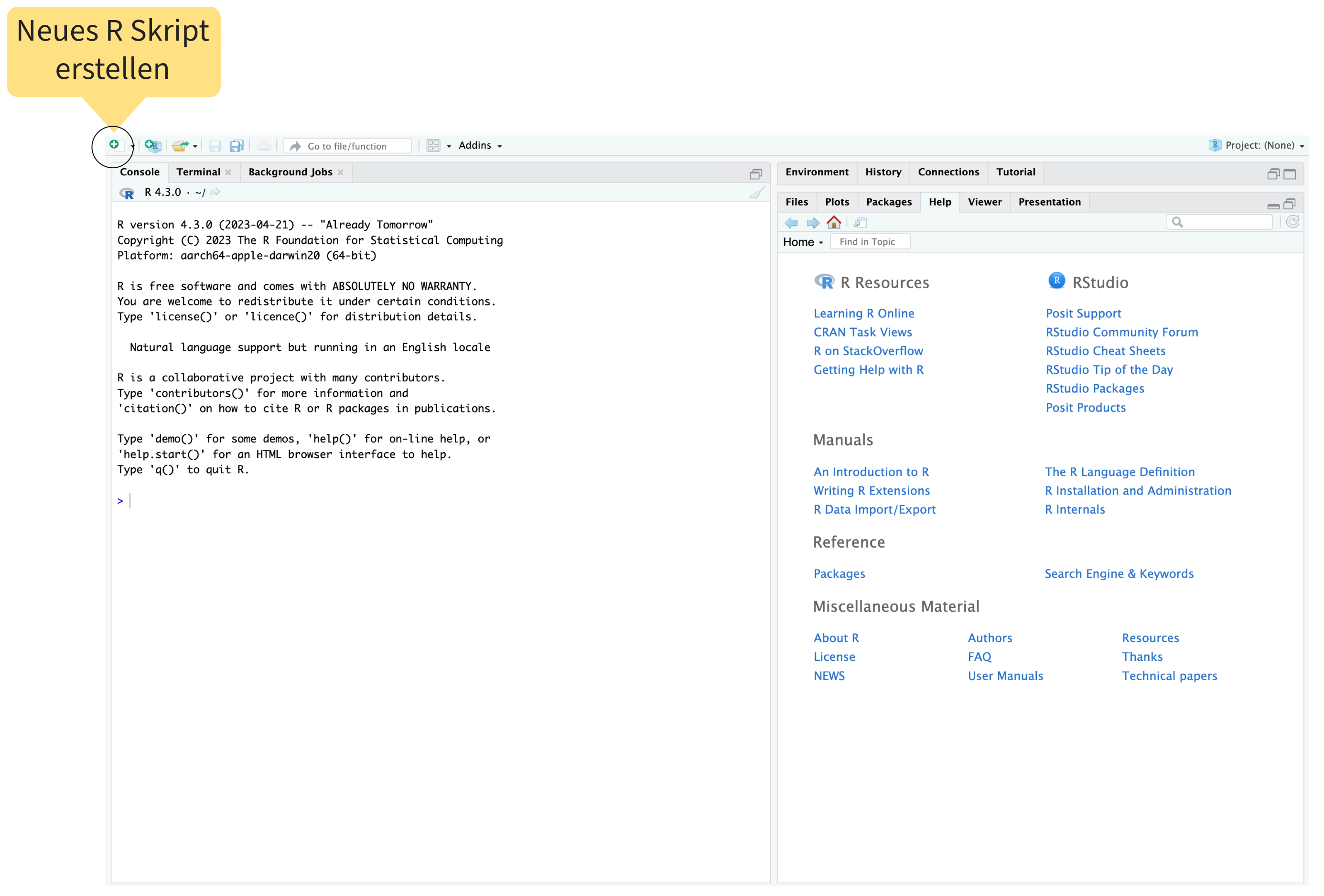
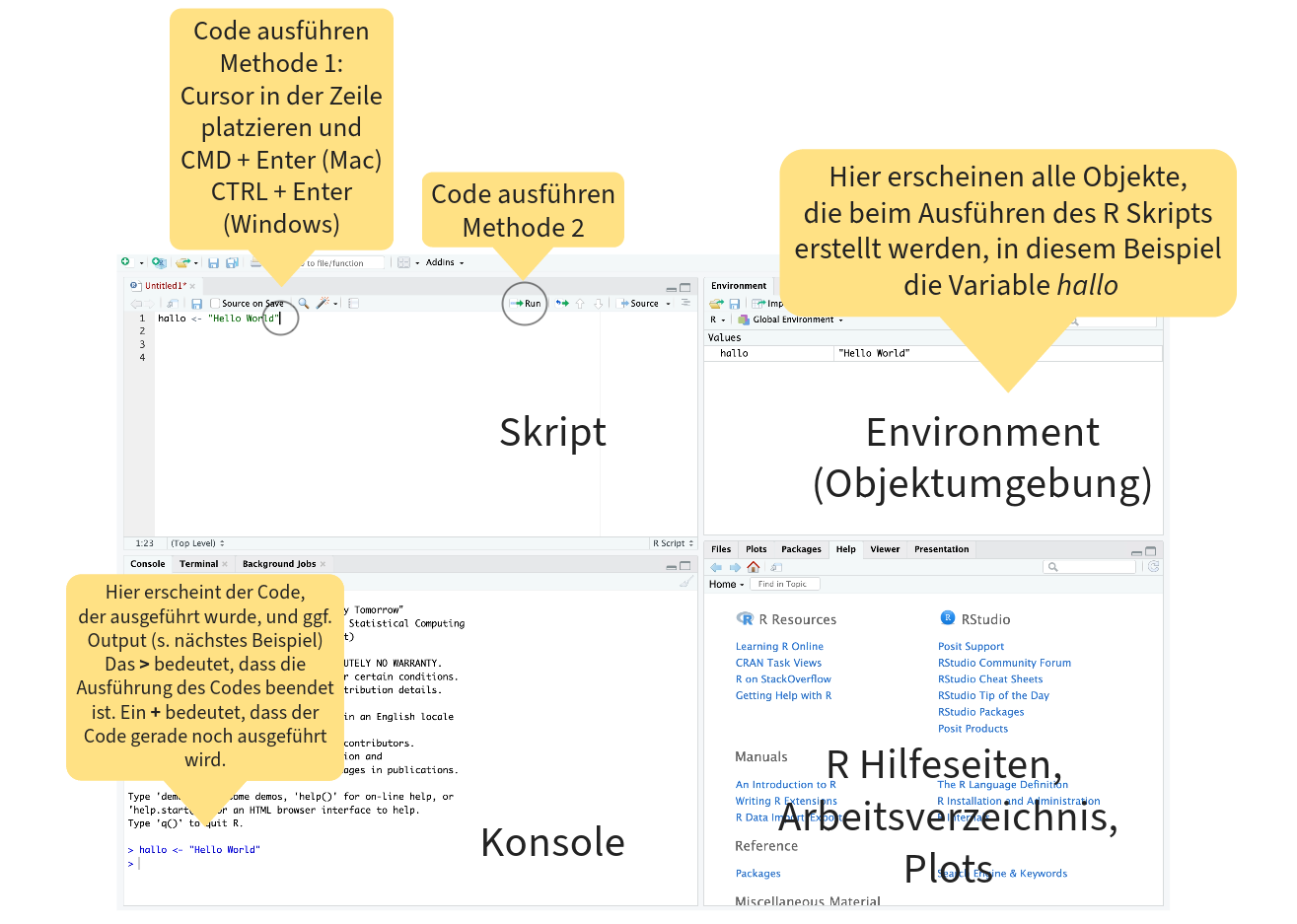
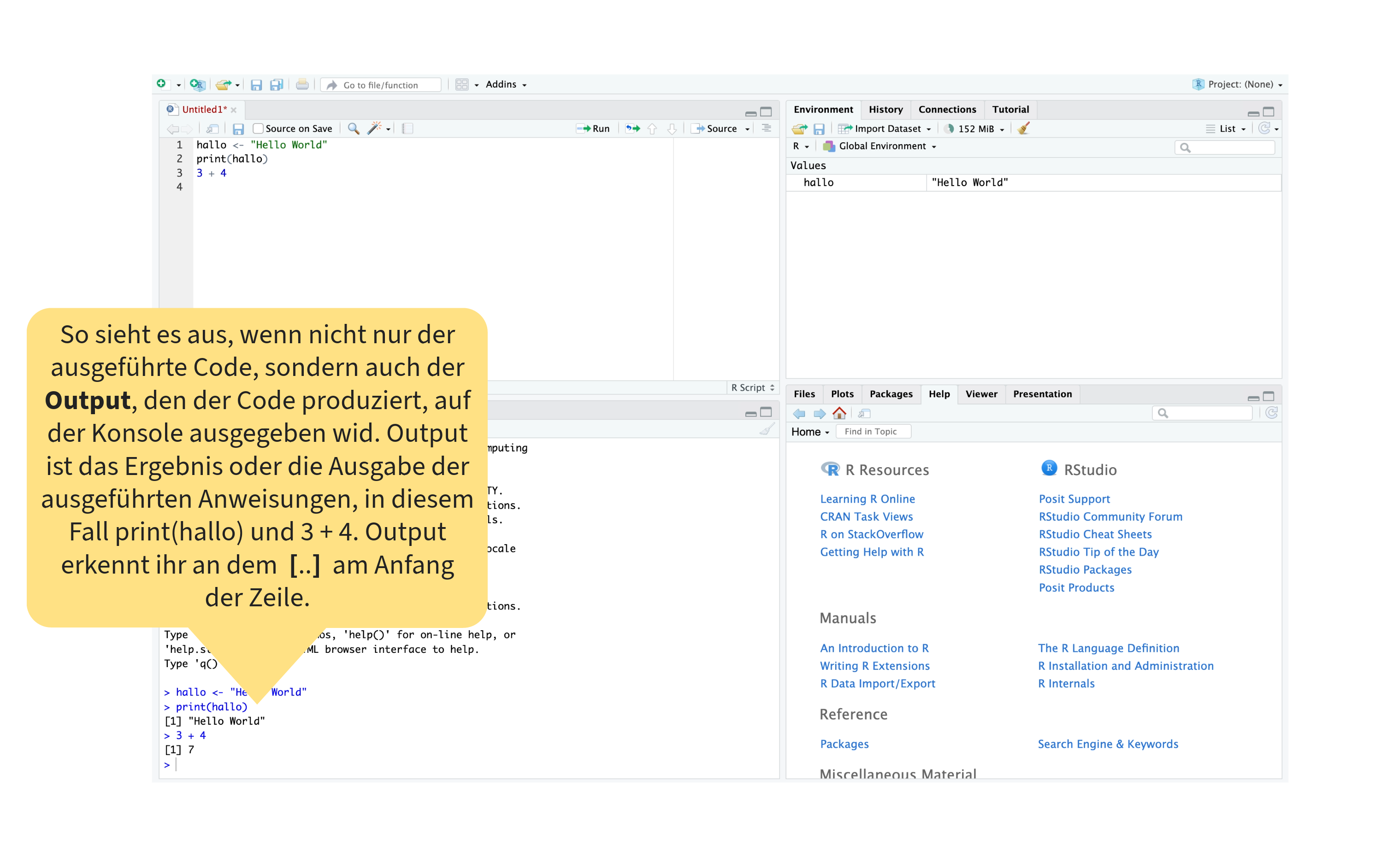
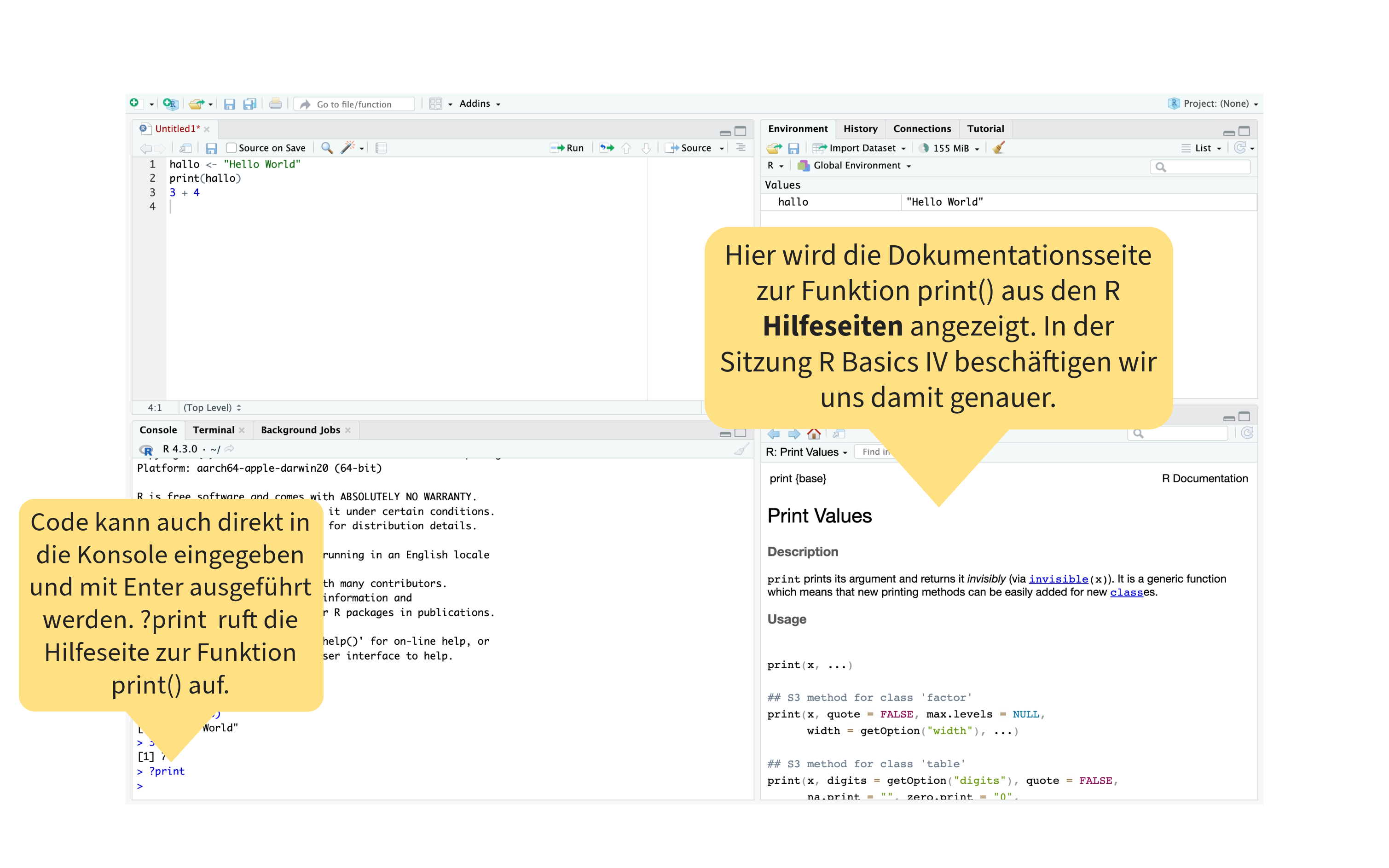
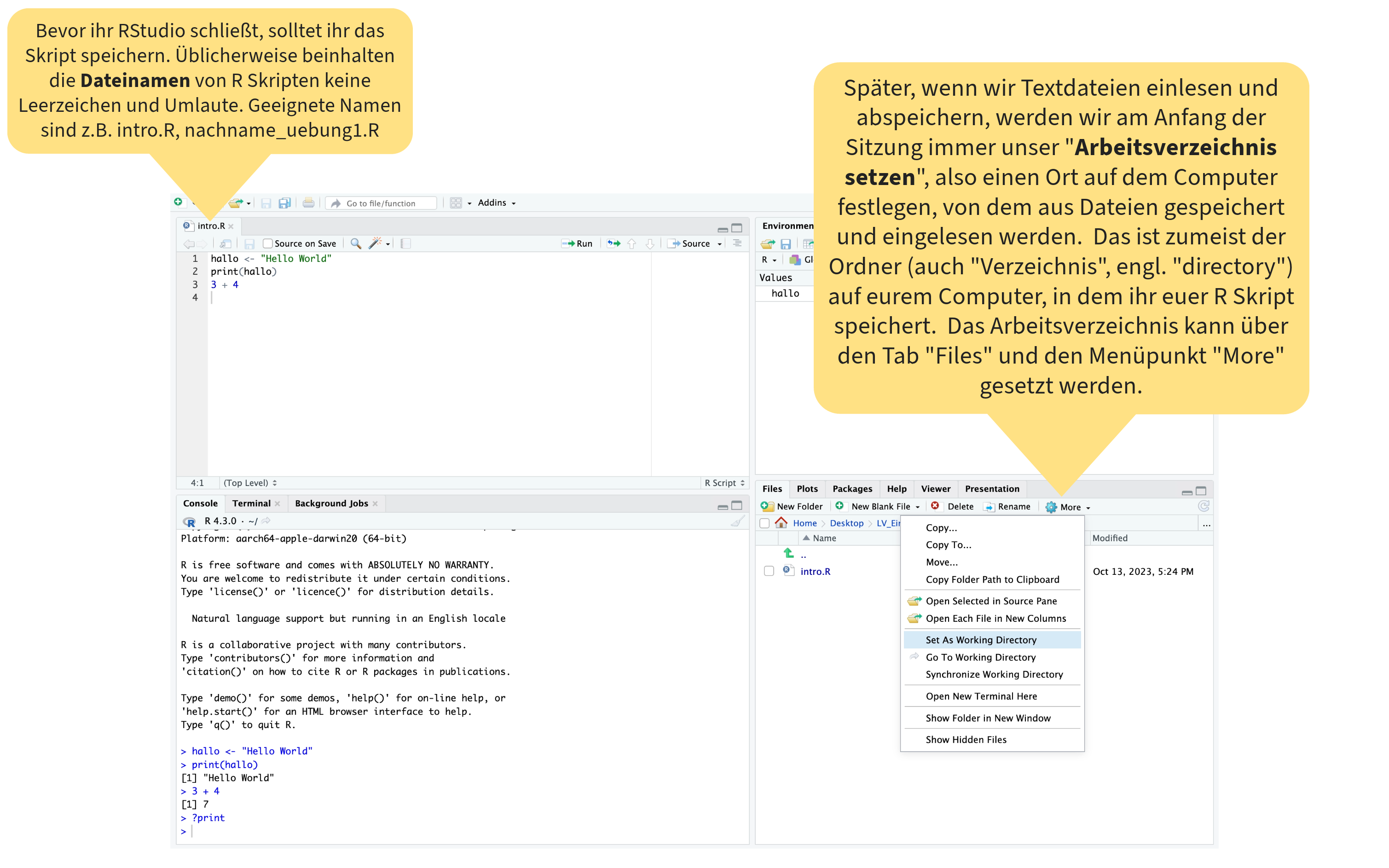
Orientierung im RStudio
1
R Basics I: Datentypen, Variablen und Operatoren
1.1
Grundlegende Begriffe
1.2
Style Guide
1.3
Kommentare
1.4
Datentypen
1.5
Operatoren
1.6
Variablen
1.7
Operatorpräzedenz
Quellen
2
R Basics II: Datenstrukturen
2.1
Grundlegende Begriffe
2.2
Vektoren
2.2.1
Sets (Mengen)
2.2.2
Named Vectors
2.2.3
Faktoren
2.2.4
Zugriffsoperationen auf Vektoren
2.2.5
Vektorisierung
2.3
Listen
2.3.1
Zugriffsoperationen auf Listen
2.4
Auf einen Blick: Vektoren vs benannte Vektoren vs Faktoren vs Listen
2.5
Matrizen
2.5.1
Zugriffsoperationen auf Matrizen
2.6
Arrays
2.6.1
Zugriffsoperationen auf Arrays
2.7
Dataframes
2.7.1
Zugriffsoperationen auf Dataframes
2.8
Auf einen Blick: Matrizen vs Arrays vs Dataframes
2.9
Datenstrukturen untersuchen
2.10
Fehlende und ungültige Werte in Datenstrukturen
2.11
Der Mitgliedschaftsoperator %in%
2.12
Unveränderbarkeit von Objekten in R
Quellen
3
R Basics III: Kontrollstrukturen
3.1
Bedingte Anweisungen
3.2
Verzweigungen
3.3
while-Schleifen
3.4
for-Schleifen
3.5
Schleifen abbrechen
Quellen
4
R Basics IV: Funktionen und Pakete
4.1
Was sind Funktionen?
4.2
Funktionen definieren
4.3
Funktionen aufrufen
4.4
Funktionen verstehen
4.5
Wozu werden Funktionen verwendet?
4.6
Schleifen ersetzen mithilfe von Funktionen
4.6.1
Die Apply-Funktionen
4.7
Gültigkeit der Funktionsargumente überprüfen
4.8
Funktionsumgebung und Sichtbarkeitsbereich von Variablen
4.9
Was sind Pakete?
4.10
Pakete installieren
4.11
Pakete laden
4.12
Wozu werden Pakete verwendet?
4.13
Welche Pakete gibt es denn alles?
Quellen
5
Textanalyse I: Korpus, Tokens, Daten und Dateien
5.1
Was sind eigentlich Daten?
5.2
Korpus, Tokens und Types
5.3
Überblick: Textanalyse mit Quanteda
5.4
Textdateien einlesen
5.5
Quanteda corpus-Objekte
5.6
Quanteda tokens-Objekte
5.7
Quanteda DFM-Objekte
5.8
Daten schreiben
Quellen
6
Exkurs: Reguläre Ausdrücke
6.1
Was sind reguläre Ausdrücke?
6.2
Reguläre Ausdrücke in R
6.2.1
R Base Funktionen
6.2.2
Spezielle Pakete: stringr
6.3
Regex Syntax
6.3.1
Basics Syntax
6.3.2
Zeichenklassen
6.3.3
Lookarounds
6.4
Regex für nicht-lateinische Schriften
Weiterführende Links
7
Textanalyse II: Preprocessing
7.1
Tokenisieren und segmentieren
7.2
Reguläre Ausdrücke im Preprocessing
7.3
Satzzeichen, Zahlen und Sonderzeichen entfernen
7.4
Stoppwörter entfernen
7.5
Groß- und Kleinschreibung anpassen
7.6
Stemming
7.7
Lemmatisierung
7.7.1
Methode 1: Lemmatisierung mit Lexikon
7.7.2
Methode 2: Lemmatisierung mit UDPipe
Quellen
8
Textanalyse III: Wortfrequenzanalysen
8.1
Märchenkorpus einlesen und Pakete installieren
8.2
Corpus-Objekt erstellen und Preprocessing
8.3
Token-Häufigkeitsanalyse
8.4
Keywords in Context (KWIC)
8.5
N-Gramme
8.6
Kookkurrenzen
8.7
Kollokationen
8.8
Keyness-Analyse
8.9
TF-IDF
8.10
Exkurs: Lexikalische Vielfalt
8.11
Recap und Ausblick
Quellen
9
POS Tagging und Dependency Parsing
9.1
Recap UDPipe
9.2
Part of Speech Tagging mit UDpipe
9.3
Dependency Parsing mit UDPipe
9.4
Beispielanalyse: Märchen
9.4.1
Korpus einlesen und Preprocessing
9.4.2
Analyse mit POS Tags
9.4.3
Analyse mit Dependency Relations
9.5
Fazit
Quellen
10
Named Entity Recognition
10.1
Korpus einlesen
10.2
Beispiel mit SpaCy / Spacyr
10.3
Beispiel mit Flair / FlaiR
10.4
Vergleich und Ausblick
Quellen
11
Exkurs: XML, TEI und XPath
11.1
Was ist XML? Was ist TEI?
11.2
Aufbau von XML-TEI Dokumenten
11.3
Wohlgeformtheit und Validität
11.4
Wo findet man Korpora, die in XML-TEI ausgezeichnet sind?
11.5
Was ist XPath?
11.6
Basics XPath Syntax
Weiterführende Links und Literatur
12
Arbeit mit XML-TEI-Dokumenten
12.1
Beispiel Dramenanalyse
12.2
Beispiel Geomapping
12.2.1
Geoname-IDs aus der XML-TEI-Datei extrahieren
12.2.2
Koordinaten über die Geonames-API abrufen
12.2.3
Koordinaten auf Karte abbilden
Quellen
Published with bookdown
Einführung in R: Programmieren für die Geisteswissenschaften
Orientierung im RStudio